Greg
-
Gesamte Inhalte
1.044 -
Registriert seit
-
Letzter Besuch
Alle erstellten Inhalte von Greg
-

MsSQlServer 2005 Trigger funzt nicht keine Errormessage
Greg antwortete auf ein Thema von ingoeff in: MS SQL Server Forum
Hallo Ingoeff Schau mal nach ob der Trigger deaktiviert ist: USE [DEINE DB] SELECT name , type_desc , create_date , modify_date , is_disabled FROM sys.triggers Gruss Gregory -
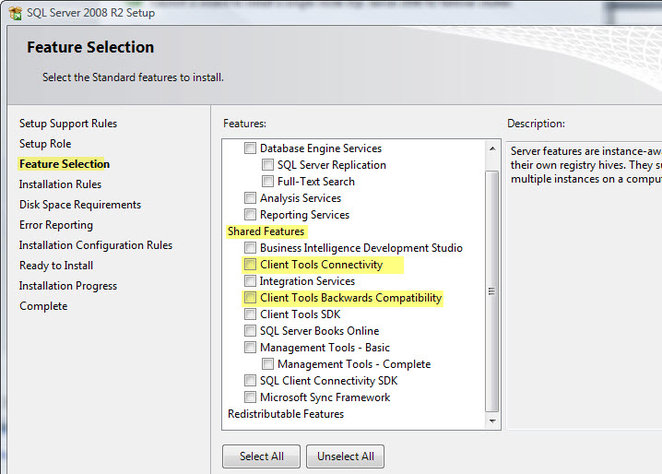
Hallo Frogger Die von Dir angesprochenen Tools sind beim "normalen" Setup dabei (siehe Bild im Anhang). Gruss Greg

-
Was sagt die folgende Abfrage? Select * from sys.servers Gruss Greg
-
Hast du den Server bzw den SQL Service nach der Umbenennung mal neu gestartet? Gruss Greg
-
Und das ist falsch? Gruss Greg
-
Hallo karkenau Der erste Teil der Fehlermeldung bezieht isch auf den ersten Teil des Befehls den du abgesetzt hast (EXEC sp_dropserver 'hier_der_alte_Rechnername'). Kannst Du bitte mal den Vorschlag der Fehlermeldung durchführen (sp_helpserver) und das gesamte! Resultat hier posten? Gruss Greg
-
Hallo Ghost Das ist wichtig. Zumindest solltest Du erst mal lesen, was Maintenace Plans und Jobs sind. Ich kann mir kaum vorstellen, das Dein Chef da was dagegen hat. Er ist wahrscheinlich auch froh, wenn das dann nachhaltig läuft. Hier mal vorab zwei Links How to: Create a Maintenance Plan How to: Create a Job (SQL Server Management Studio) Wenn Du die von SQL Server bereitgestellten Index Wartungs Jobs verwenden willst, dann mach einen Wartungsplan mit zwei Zeitplänen, in welchem Du die Index Wartung wie gewünscht einrichten und konfigurieren kannst. Wenn Du dem Microsoft Script einfach vertrauen willst (sieht übrigens nicht schlecht aus) dann kannst Du auch einfach einen SQL Server Agent Job einrichten welcher als Job-Step das Micorosft Script beinhaltet. Diesen Job kannst Du dann auch zeitlich planen. Siehe dazu folgenden Link: How to: Create a Transact-SQL Job Step (SQL Server Management Studio) Wenn Dir die Fachbegriffe in diesem Post zu viel sind, dann hol Dir Hilfe ins Haus. Gruss Greg
-
Hallo Callium Für mich ist hier auch die Antwort 3 richtig. Dies auf Grund des folgenden Artikels: ALTER TABLE (Transact-SQL) Dort steht: Meiner meinung nach deckt sich das genau mit der von Dir beschriebenen Aufgabe. Je nach Art und Herkunft deiner "Übungsfragen" sind die Antworten nicht immer richtig! Gruss Greg
-
Microsoft SharePoint 2010 70-667 bestanden
Greg antwortete auf ein Thema von Greg in: MS Zertifizierungen — Prüfungen
Hallo zusammen @Fr33climber Wir haben hier im letzten Halbjahr eine grössere Sharepoint 2010 Umgebung installiert. Dies zusammen mit den Büchern von Wrox (bin Member deren Online Library) war eine gute Vorbereitung. @r2k Vom Schwierigkeitsgrad fand ich die 667 einiges schwieriger. Vergleichbar von den Fragen her sind die Prüfungen nur bedingt da mit den ganzen Service Applications auch das Produkt anderst aufgebaut ist. Gruss Greg -
Microsoft SharePoint 2010 70-667 bestanden
Greg hat einem Thema erstellt in: MS Zertifizierungen — Prüfungen
70-667: Microsoft SharePoint 2010 bestanden :D Zeit: 2h30min Fragen: 50 Pass: bei 70% Fragen zum Thema Konfiguration der Service Applications, Alternate Access Mapping, Authentication Provider, Environment, Resource Throtteling, Logging, Umzug von Datenbanken, Webanalytics, Secure Store Service, etc. Auffallend viele Fragen zum Thema Backup/Restore! Bei Fragen einfach posten ... Schönes Week End Gruss Greg -
SQL DB auf neuen Server umziehen - für Dummies
Greg antwortete auf ein Thema von wolkenloser in: MS SQL Server Forum
Hallo Wolkenloser Für den Umzug der DB anbei zwei Artikel: How to: Move a Database Using Detach and Attach (Transact-SQL) How to move databases between computers that are running SQL Server (schon älter aber von der Vorgehensweise her ok) Übertragen der User auf den neuen Server: Übertragen von Benutzernamen und Kennwörtern zwischen Instanzen von SQL-Server (Ist für SQL 2005 geht aber auch für SQL 2008, habs versucht ...) Gruss Gregory -
Hallo zusammen Ich möchte euch gerne folgende Erfahrung weitergeben, welche wir hier bei uns gemacht und nachgestellt haben. Vieleicht stösst ja der eine oder andere auch mal auf das Problem: Problem: REPLData Folder der Snapshot Replikation wurde nicht zeitlich gesteuert "gereinigt", was eigentlich automatisch passieren sollte. Gegebenheit: Bei der Installation des SQL Servers wurde mittels Skript die Replikation als Feature mit installiert. ABER: Die der Replikation zugehörenden SQLAgent Jobs werden erst bei der Erstellung der ersten Publikation erzeugt. Verhalten: Wird beim Erstellen der ersten Publikation über den Wizard eine Snapshot Publikation erstellt und im Fenster [specify when to run the snapshot agent] [Create a Snapshot immediately …] ausgewählt, wird der Job [Distribution Cleanup: Distribution] im SQLAgent nicht erstellt. Auswirkung: Disk auf der die ReplData Folders liegen, läuft voll. Je kleiner der Replikationsintervall konfiguriert wird, umso schneller ist die Disk voll. Lösung: Entweder die Replikation direkt im Wizard planen (Schedule the Snapshot Agent to run at the following times) oder mindestens den Job [Distribution Cleanup: Distribution] manuell erstellen (Skript dazu siehe Anhang). Weitere Infos: Die (Snapshot) Replikation benötigt folgende SQLAgent Jobs: • Agent history clean up: distribution ○ Startet: EXEC dbo.sp_MShistory_cleanup @history_retention = 48 • Distribution clean up: distribution ○ Startet: EXEC dbo.sp_MSdistribution_cleanup @min_distretention = 0, @max_distretention = 72 • Replication agents checkup ○ Startet: sys.sp_replication_agent_checkup @heartbeat_interval = 10 • Reinitialize subscriptions having data validation failures ○ Startet: exec sys.sp_MSreinit_failed_subscriptions @failure_level = 1 • Replication monitoring refresher for distribution(deaktiviert) ○Startet: exec dbo.sp_replmonitorrefreshjob Dies zur Info. Freue mich natürlich um Berichtigungen und Anmerkungen Gruss Greg Create_Distribution_Cleanup_Distribution_Job_sql.txt
-
Hallo zusammen Standardmässig packt Sharepoint alles in die Content-Datenbanken. Wenn Du das umkonfigurieren möchtest, kannst Du Filestream verwenden. Dazu musst Du allerdings auch den Sharepoint Server richtig konfigurieren. Siehe dazu: Install and configure Remote BLOB Storage (RBS) with the FILESTREAM provider (SharePoint Server 2010) Folgendes ist aber auch wichtig: Die Performance von Sharepoint Server 2010 ist direkt von der Leistungsfähigkeit des SQL Servers abhängig. Auf Grund der Limitationen der SQL Express Version ist diese Kombination nur für Kleinstumgebungen oder Test- und Entwicklungsserver (Single Server) sinnvoll. Siehe dazu: Hardware and software requirements (SharePoint Server 2010) Hardware and software requirements (SharePoint Foundation 2010) Gruss Gregory
-
Hallo phoenixcp Auch ok. Würde mich freuen, wenn Du dich an diesem Austausch dann beteiligen kannst ... Nein, ist noch keine Notwendigkeit vorhanden. Ich weiss aber, dass HADR und Contained Databases sicher interessant sind für uns. Was bei uns im Raum steht ist die Reorganisation und Konsolidierung der SQL Server Umgebung, da wir aus historischen Gründen einfach zu viele SQL Server haben. Nun ist halt die Frage aufgekommen, ob man sich für dieses Projekt grad mit der neuesten Version befassen soll um mit den neuen Möglichkeiten zu konzeptionieren. Persönlich möchte ich einfach einmal früh bereit sein für das neue Produkt. Da kann ich Dir aus eigener leidlicher Erfahrung nur Recht geben. Ist vor allem auch bei kleineren Software-Lieferanten nicht immer einfach, eine Aussage zum Thema "Versions-Kompatibilität" zu erhalten. Danke für Dein Feedback. Gruss Gregory
-
Hallo zusammen Microsoft hat ja vor einiger Zeit die CTP zur neuen SQL Server Ausgabe Denali (möglicherweise SQL 2012) online gestellt. Microsoft SQL Server Future Editions | A complete set of enterprise-ready technologies and tools SQL Server Denali Ich möchte mir demnächst eine kleine Testumgebung aufbauen um die neuen Features mal genauer anzuschauen. Darum hier meine Frage: Arbeitet (testet) Ihr schon mit dem neuen SQL Server? Wenn ja, wäre es eine Idee hier im Forum einen Austausch zum Thema Denali zu gestalten? Wie könnte man das angehen? Bitte schreibt mir doch Eure Ideen und Gedanken. Gruss und Dank Greg
-
Fehler (Meldung 601; Scan mit NOLOCK konnte ...) bei Datenbank anhängen mit .mdf
Greg antwortete auf ein Thema von joshihybrid in: MS SQL Server Forum
Hallo joshihybrid Sichere (kopiere) Dir die ursprünglichen Files (mdf/ldf) mal irgendwohin, damit du sie im aktuellen Zustand auf der Seite hast. Danach teste den den KB Artikel aus, welchen Du von MVP Elmar Boye im Microsoft SQL Forum erhalten hast. Wie Fehler (Meldung 601; Scan mit NOLOCK konnte ...) bei Datenbank anhängen mit .mdf beheben? Wenn Du das getan hast sind wir hier über eine Rückmeldung froh. Sollte das keinen Erfolg haben, dann wird kein Weg an einem Microsoft Support Call vorbeiführen. Denen solltest Du dann aber genau erklären was war und dich für eine Deiner Varianten entscheiden. Je nachdem welchen Status Du bei Microsoft hast, wird das dann halt was kosten ... Nebst dem Microsoft SQL Server Forum gibt es für mich in solchen Fragen noch die Website SQLServercentral.com. Ich habe in solchen Fällen schon mehrere Male Top-Leute gefunden, welche helfen konnten. (@Admins: Falls ich den Link nicht posten durfte, einfach löschen) Gruss Greg -
Hallo memob Vieleicht ist der folgende Artikel ein Einstiegspunkt für Dich: How to move databases between computers that are running SQL Server Gruss Gregory
-
Update Microsoft SQL 2005 Express nach Vollversion SQL 2005 Standard
Greg antwortete auf ein Thema von reiner_h in: MS SQL Server Forum
Hallo reiner h Diese beiden Artikel könnten für dich hilfreich sein: Hardware and Software Requirements for Installing SQL Server 2005 How to: Upgrade to SQL Server 2005 (Setup) Gruss Greg -
Fehler bei Verkleinern für DataFile
Greg antwortete auf ein Thema von Spacemarco in: MS SQL Server Forum
Hallo zusammen Hab ich selber noch nie gehabt, aber: Das Shrinken der Datenbankfiles ist auch online möglich. Ich habe das getestet mittels GUI und mittels Script. Spontan hatte ich die Idee: Ist evtl. Autoshrink eingeschaltet auf diese Datenbank? Dann noch folgende interessanten Links zum Thema Databasefile-Shrinking: In Recovery... | Why you should not shrink your data files In Recovery... | A SQL Server DBA myth a day: (9/30) data file shrink does not affect performance Gruss Greg -
Hallo Maguro Ja das ist so. Jede Instanz benötigt eigene Laufwerke. Wenn Du so viele Laufwerke benötigst dass die Laufwerksbuchstaben knapp werden, kannst Du auch mit Mountpoints anstelle von Laufwerksbuchstaben arbeiten. Schau mal in den folgenden Thread. Dort sind viele interessante Links zum Thema drin: http://www.mcseboard.de/ms-sql-server-forum-81/sql-w2k8r2-konfiguration-169786.html Gruss Greg
-
Hallo derhoeppi Bitte konsultiere doch die in diesem Thread zahlreich angegebenen Links und Vorschläge. Der MS Cluster muss fertig gebaut sein bevor Du den SQL Cluster darauf bauen kannst. Der SQL Cluster basiert auf den Cluster Services des Betriebsystemes. Weiterer Tipp: Such doch mal bei Google nach dem folgenden eBook: --> Pro SQL Server 2008 Failover Clustering von Allan Hirt Lies das, und Du wirst Deinen Cluster problemlos zum laufen bekommen. Gruss Greg
-
Hallo derhoeppi Richtig: Windows Server 2008 R2 - Technische Spezifikationen der Editionen im Vergleich Gruss Greg
-
Failover Clustering kannst Du so nicht verwenden ausser Du baust eine Verbindung vom 2. Standort zum Storage. Irgendeine Verbindung der beiden Standorte muss es ohnehin geben, wenn du High Availibility verwenden möchtest. Aus Deinen Schilderungen würde ich mich unbedingt noch in Richtung Database Mirroring im High Safety Mode informieren. http://technet.microsoft.com/en-us/library/ms179344.aspx Wir haben lange hin und her diskutiert bevor wir uns dann doch für einen Failover Cluster entschieden haben. Würde mich freuen, von Deinen Entscheidungen dann zu hören. Gruss Greg
-
Hallo derhoeppi Das ist meines Wissens falsch. Du kannst auch Aktiv/Aktiv betreiben, einfach eingeschränkt auf maximal zwei Nodes. Für den Bau eines Failover Clusters (unabhängig davon ob aktiv/aktiv oder aktiv/passiv) müssen beide Server (Nodes) Zugriff auf den Storage haben! Gruss Greg
-
Hallo miteinander Hier meine Erfahrungen zum Thema SQL Cluster ... Zuerst einmal: Wenn ein Failovercluster benötigt wird, muss man sich zuerst einmal Gedanken dazu machen, ob man sich vieleicht externe Hilfe holen sollte. Einen Cluster baut man ja nicht zum Spass sondern damit man nacher ein höheres Verfügbarkeitsniveau hat. Wir haben externe Hilfe geholt für den Bau unserer Sharepoint 2010 Umgebung wo wir zwei Cluster gebaut haben. Zum Sizing: Meiner Meinung nach muss man zuerst die Datenbankcharakteristiken im Bereich Read/Write/IOP's kennen. Dann kannst Du die Disks so auslegen, damit du die besten Resultate rausholst. Da für einen Cluster so oder so gesharter Storage nötig ist, kannst Du dort je nach Budget optimal zusammenstellen, was du brauchst. --> Bevor Du SQL installierst, Performance-Test machen. BSP mit SQLIO.exe How to use the SQLIOSim utility to simulate SQL Server activity on a disk subsystem Grundsätzliches zum SQL Aufbau: - DB-Files von Logfiles trennen (DB Files eher Read, Logfiles eher Read) - Temp-DB auf eigene Disks (oder LUN's) - Betriebssystem auf eigene Disks (oder LUN's) Zu aktiv/aktiv, aktiv/passiv Tote Hardware hast Du so oder so. Denn: 1. Wenn Du nur eine DB haben wirst läuft diese immer nur auf einem Node 2. Bei mehreren Datenbanken musst du auch mehrere Instanzen haben wenn du diese auf mehrere Nodes verteilen möchtest (das wäre dann MS aktiv/aktiv). "Richtiges" Aktiv/Aktiv so wie Oracle wo eine DB auf zwei Nodes läuft kann MS SQL nicht (Wurde mir so von Microsoft bestätigt). 3. Bei zwei (oder auch mehr) Datenbanken wäre allenfall das Database Mirroring im High Safety Mode ein Thema. Dort kann man zwei SQL Server unabhängig von einander verwenden (kein Shared Storage nötig) und dann mittels zwei Instanzen über Kreuz spiegeln. Nachteil: Braucht einen Witness Server. Dieser kann aber auch eine Express Version sein. Maintenance: Die Erstellung eines SQL Clusters ist keine Kunst. Die Kunst besteht danach im Betrieb und Troubleshooting eines Solchen. Einige Sachen verhalten sich anderst und müssen auch anderst gewartet werden. Einige Links die uns geholfen haben: High Availability Solutions Overview Planning and Architecture (Database Engine) SQL Server 2008 Failover Clustering - Whitepapers http://download.microsoft.com/download/B/E/1/BE1AABB3-6ED8-4C3C-AF91-448AB733B1AF/Analyzing%20Characterizing%20and%20IO%20Size%20Considerations.docx SQLCAT Whitepaper über Analyzing I/O Characteristics and Sizing Storage Systems for SQL Server Database Applications Betriebssystem und SQL Version: Wichtig ist, dass Du Dir sicher bist, dass Du nur zwei SQL Nodes brauchst. Denn wenn Du irgendwann noch Nodes dazubauen willst, musst Du dich jetzt schon für die SQL Server Enterprise Edition entscheiden. Auf jeden Fall würde ich mich für R2 entscheiden, weil da noch einiges an Verwaltungsmöglichkeiten dazugekommen sind. Soweit mal vorerst. Wenn Du noch mehr Infos brauchst, einfach melden. Gruss Greg