Alle Aktivitäten
Dieser Verlauf aktualisiert sich automatisch
- Letzte Stunde
-

Abbrüche Failover-Cluster HyperV Netzwerkkarte trennt sich
illuminaten antwortete auf ein Thema von illuminaten in: Windows Server Forum
Physische Adapter: Je Host: 2 × Intel X710-10 Gbit Ports (für Cluster) Zusätzlich: 1 × Intel I350-T4 1 Gbit Port (für anderes Netz) vSwitches: 10G-Failover: Externer vSwitch, an beide 10 G-Ports (X710-T2L + X710-TL) angebunden Typ: Switch Embedded Teaming (SET) Teaming-Modus: Switch Independent AllowManagementOS: True -

Abbrüche Failover-Cluster HyperV Netzwerkkarte trennt sich
testperson antwortete auf ein Thema von illuminaten in: Windows Server Forum
Hi, wie sieht denn die Netzwerkkonfig generell aus? Wie viele Adapter gibt es und wofür? Wie sind die geteamed (LBFO vs. Switch Embedded)? Gruß Jan -
Abbrüche Failover-Cluster HyperV Netzwerkkarte trennt sich
illuminaten antwortete auf ein Thema von illuminaten in: Windows Server Forum
Der Host selbst läuft in der Energieverwaltung auf "Höchstleistung". Bei der Netzwerkkarte ist der Haken nicht gesetzt bei "Computer kann das Gerät ausschalten um Energie zu sparen" -

Abbrüche Failover-Cluster HyperV Netzwerkkarte trennt sich
tesso antwortete auf ein Thema von illuminaten in: Windows Server Forum
Alles auf Höchstleistung? Energie sparen bei den Netzwerkkarten deaktiviert? -
Abbrüche Failover-Cluster HyperV Netzwerkkarte trennt sich
illuminaten antwortete auf ein Thema von illuminaten in: Windows Server Forum
Intel_LAN_ProSet_All Treiber ist die Version 9.01.04.00 installiert. Eine neuere Version 9.02.04.00 wäre verfügbar. Die Disks wurden immer zwischen 18 und 19 Uhr getauscht. Die Ausfälle der Netzwerkkarte war immer in Nacht, jeweils um 01:00 Uhr und gegen 02:00 Uhr - Heute
-

Abbrüche Failover-Cluster HyperV Netzwerkkarte trennt sich
v-rtc antwortete auf ein Thema von illuminaten in: Windows Server Forum
Hallo, Treiber, Software Stände passen? Wurde immer die Disk getauscht kurz vor den Ausfällen? Grüße -
Server2019: WDS - Installation auf PC klappt nicht - DHCP Problem
tesso antwortete auf ein Thema von fmeyer84 in: Windows Server Forum
DHCP-Optionen kontrollieren Option 60: „PXEClient“ (nur wenn DHCP und WDS auf demselben Server laufen) Option 66: IP-Adresse oder Hostname des WDS-Servers Option 67: Pfad zur Boot-Datei -

Server2019: WDS - Installation auf PC klappt nicht - DHCP Problem
fmeyer84 antwortete auf ein Thema von fmeyer84 in: Windows Server Forum
60=PXEClient 66 & 67 nicht, dazu habe ich nichts gefunden -
Abbrüche Failover-Cluster HyperV Netzwerkkarte trennt sich
illuminaten hat einem Thema erstellt in: Windows Server Forum
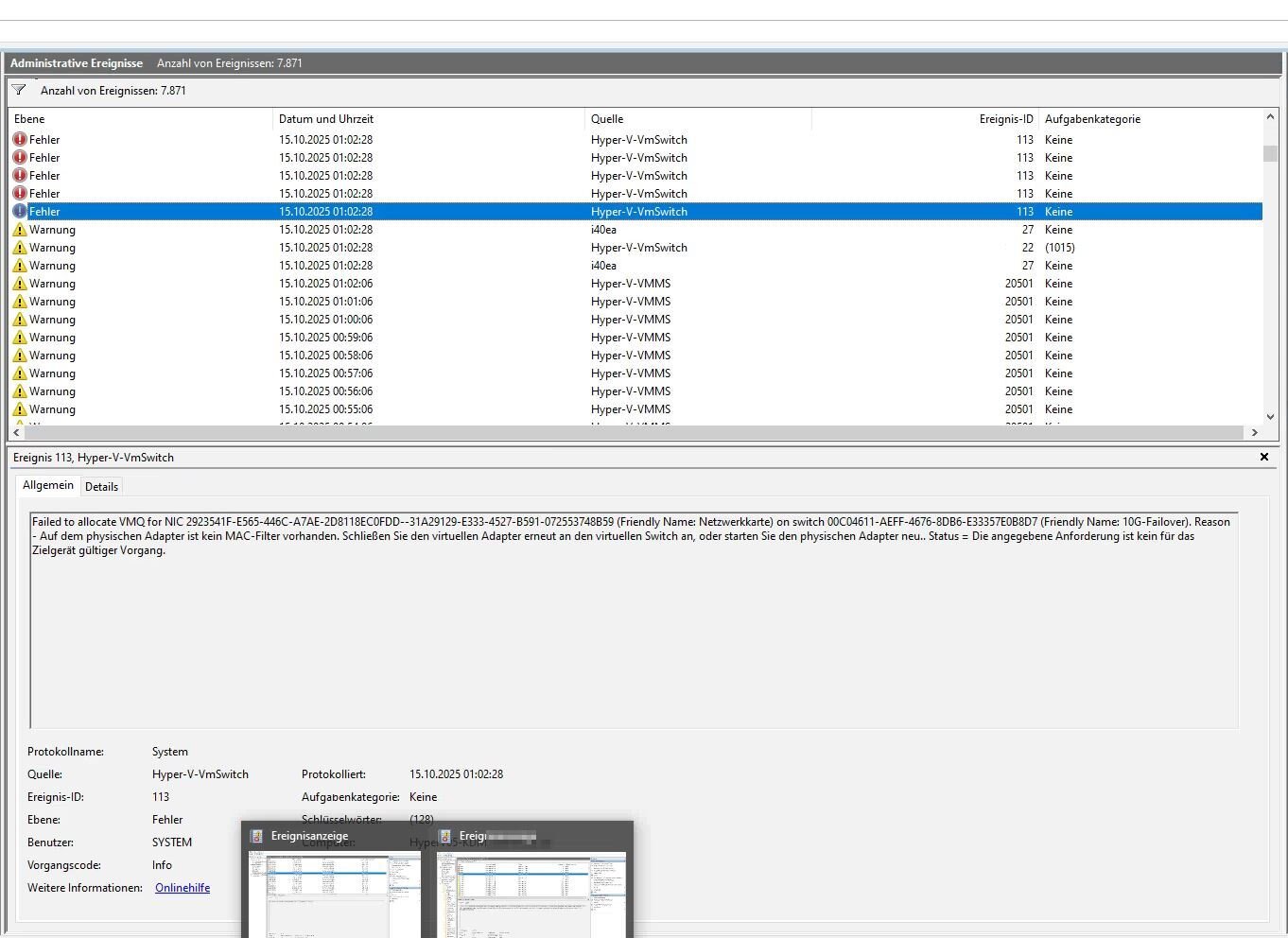
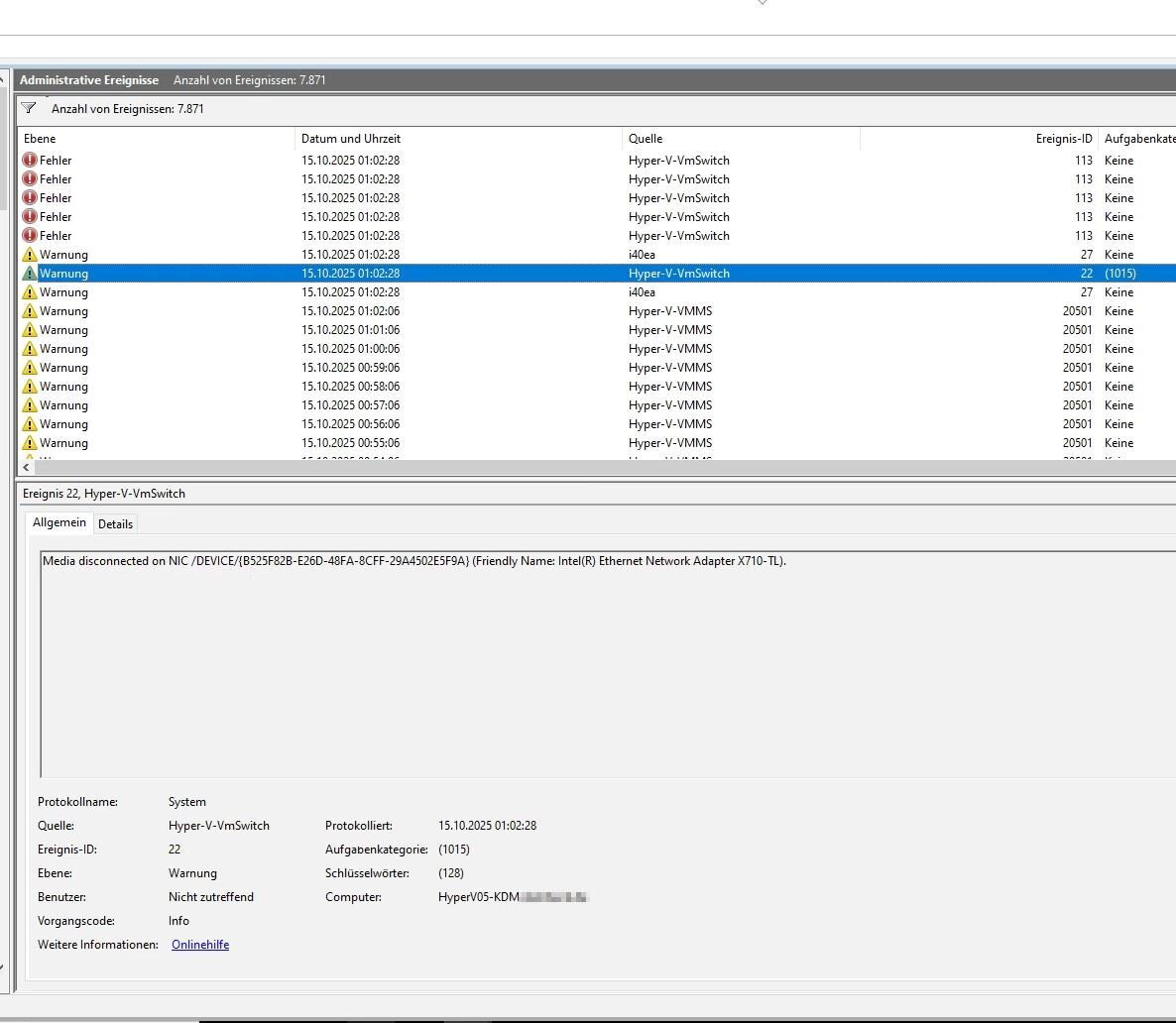
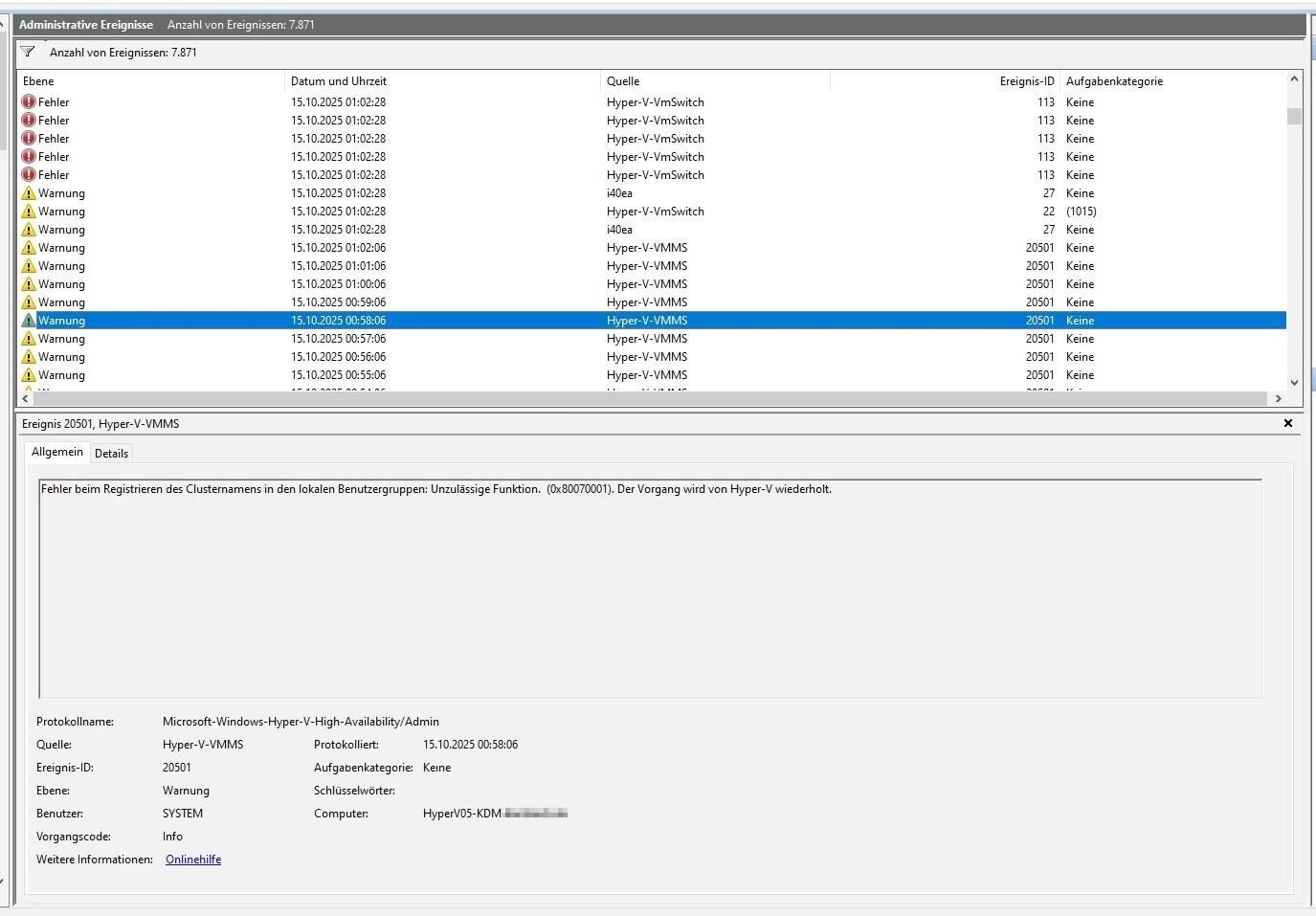
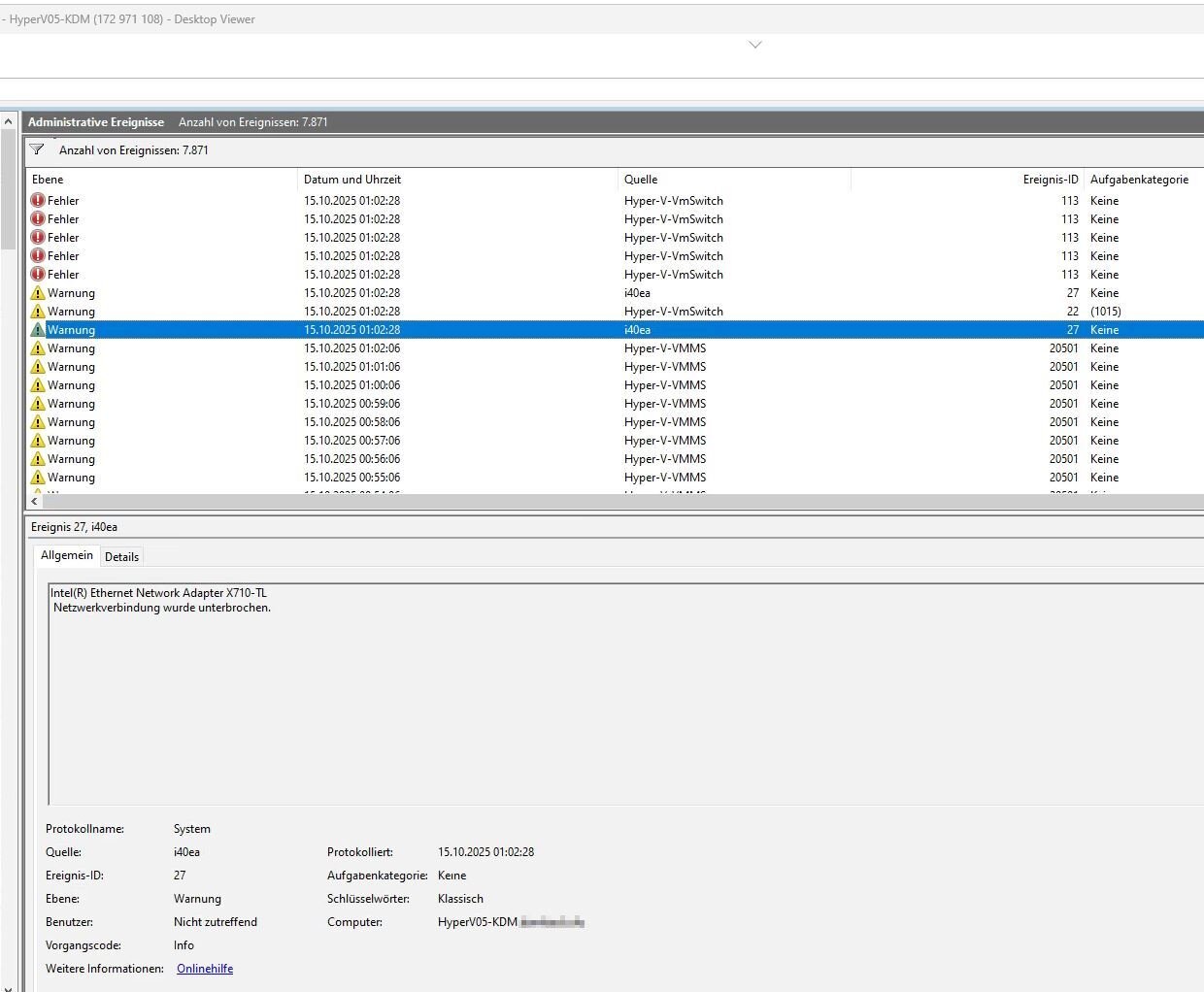
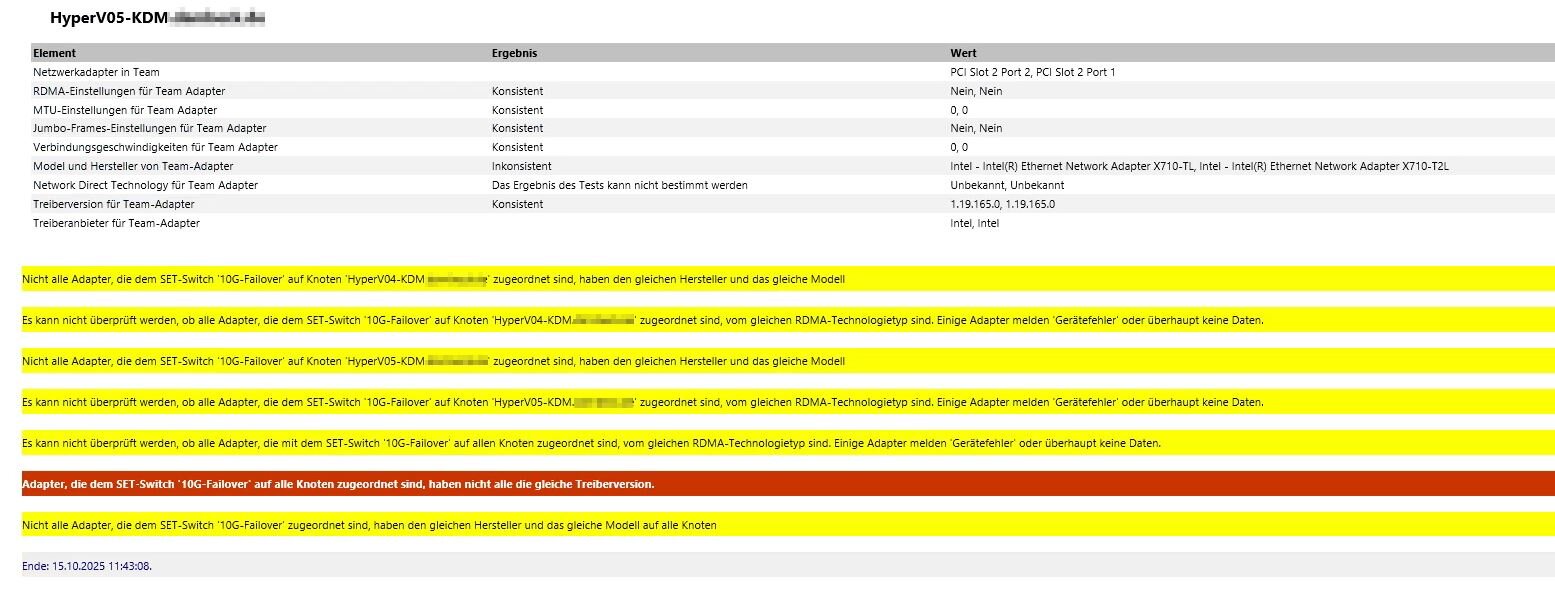
Hallo zusammen, wir haben bei einem Kunden vor ein paar Monaten zwei neue HyperV-Hosts hingestellt. Vor ca. 4 Wochen kam es dann zu einem Ausfall auf einem der Hosts. Sie sind zwar im Failovercluster, aber die angelegten VM's wurden nicht korrekt verschoben und waren in einem undefinierten Zustand. Nach Prüfung des Fehlers ist uns aufgefallen, dass am Host in der Nacht die Netzwerkkarte getrennt wurde, was dann dutzende Folgefehler produziert hat. Eine Woche später erneut der genau gleiche Ausfall. Wir haben dann alle VM's auf den zweiten Host verschoben und sind von einer defekten Netzwerkkarte ausgegangen. Nun haben wir heute den gleichen Fehler auf dem zweiten Host. Die Meldungen aus dem Ereignisprotokoll hänge ich ganz unten an. Hört sich jetzt b***d an, aber bei allen drei Ausfällen wurde vorher vom Kunden selbst die externe HDD getauscht, für die Backup Copy Jobs. Ich gehe mal nicht davon aus, dass das damit etwas zu tun haben kann, aber ich erwähne es mal lieber. Die Hosts sind: Windows Server 2022 Fujitsu PRIMERGY RX2530 M7 bzw. PRIMERGY RX2530 M7S CPU: Intel(R) Xeon(R) Gold 5416S (CORES 16) Motherboard: FUJITSU D3982-A1 Hier noch ein paar Infos zu Netzwerkkarten: Name : Flexible LOM1 Port 3 Description : Intel(R) Ethernet Network Adapter I350-T4 for OCP NIC 3.0 Manufacturer : InterfaceDescription : Intel(R) Ethernet Network Adapter I350-T4 for OCP NIC 3.0 PNPDeviceID : Name : Flexible LOM1 Port 2 Description : Intel(R) Ethernet Network Adapter I350-T4 for OCP NIC 3.0 #4 Manufacturer : InterfaceDescription : Intel(R) Ethernet Network Adapter I350-T4 for OCP NIC 3.0 #4 PNPDeviceID : Name : PCI Slot 2 Port 1 Description : Intel(R) Ethernet Network Adapter X710-T2L Manufacturer : InterfaceDescription : Intel(R) Ethernet Network Adapter X710-T2L PNPDeviceID : Name : PCI Slot 2 Port 2 Description : Intel(R) Ethernet Network Adapter X710-TL Manufacturer : InterfaceDescription : Intel(R) Ethernet Network Adapter X710-TL PNPDeviceID : Name : Onboard LAN Description : Intel(R) I210 Gigabit Network Connection Manufacturer : InterfaceDescription : Intel(R) I210 Gigabit Network Connection PNPDeviceID : Name : Flexible LOM1 Port 1 Description : Intel(R) Ethernet Network Adapter I350-T4 for OCP NIC 3.0 #3 Manufacturer : InterfaceDescription : Intel(R) Ethernet Network Adapter I350-T4 for OCP NIC 3.0 #3 PNPDeviceID : Name : Flexible LOM1 Port 4 Description : Intel(R) Ethernet Network Adapter I350-T4 for OCP NIC 3.0 #2 Manufacturer : InterfaceDescription : Intel(R) Ethernet Network Adapter I350-T4 for OCP NIC 3.0 #2 PNPDeviceID : Edit: Ich habe noch einen Screenshot angehängt von der Clusterüberprüfung. Dort gibt er mir Warnungen und Fehler bei der Switch Konfiguration aus.
-
Server2019: WDS - Installation auf PC klappt nicht - DHCP Problem
tesso antwortete auf ein Thema von fmeyer84 in: Windows Server Forum
DHCP-Optionen 60,66,67 sind korrekt konfiguriert? -

Oktober 2025 Exchange Updates
NorbertFe antwortete auf ein Thema von NorbertFe in: MS Exchange Forum
Ja hab ich neulich auch gesehen und musste etwas grinsen. -
Server2019: WDS - Installation auf PC klappt nicht - DHCP Problem
fmeyer84 antwortete auf ein Thema von fmeyer84 in: Windows Server Forum
Hallo, das ist auch eine virtuelle Maschine auf dem Proxmox. IPv6 habe ich auf dem Server deaktiviert, es ist der erste DHCP Client. -
Danke für die Info. ;) BTW: Im WSUS wird der Exchange SE als Exchange 2025 angezeigt:
-

Server2019: WDS - Installation auf PC klappt nicht - DHCP Problem
Sunny61 antwortete auf ein Thema von fmeyer84 in: Windows Server Forum
Betrifft das nur diesen einen Client? Hat der eine besondere NIC? BIOS/UEFI aktuell? Ist IPV6 bei PXE aktiv? BIOS/UEFI mal auf Default Einstellungen setzen. DHCP ist voll? - Gestern
-
Hi, Microsoft hat heute die neuesten Exchange Updates für Exchange 2016, 2019 und SE bereitgestellt. Für Exchange 2016 und 2019 sind es die letzten frei verfügbaren Updates. Weiter Infos wie immer bei MS: https://techcommunity.microsoft.com/blog/exchange/released-october-2025-exchange-server-security-updates/4461276
-
Server2019: WDS - Installation auf PC klappt nicht - DHCP Problem
fmeyer84 hat einem Thema erstellt in: Windows Server Forum
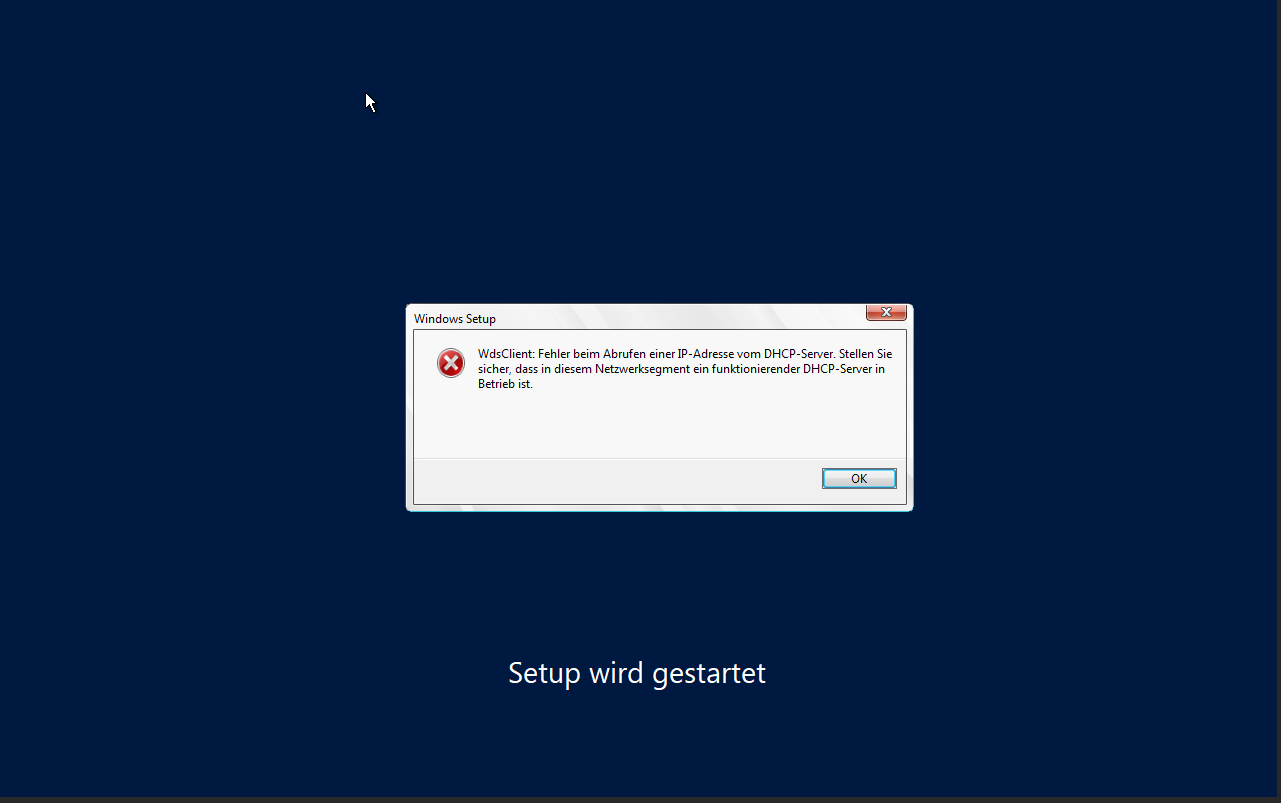
Hallo zusammen, ich habe meinen SRV2019 auf Proxmox (8.4.14) installiert mit Domäne, DHCP, DNS und WDS mit PXE usw... Soweit so gut, läuft auch. Im WDS Startabbilder (Win 10 22H2) und Installationsabbilder (Win 11 25H2) hinterlegt. Nun bootet ein PC über PXE, kriegt eine IP aus der DHCP Range des Servers - diese ist dann auch in den Adressleases im DHCP Server zu finden - bootet die boot.wim, Setup startet und dann kommt immer der angehängte Fehler. Nun dachte ich, dass es vllt daran liegt, das Win11 über WDS nicht mehr unterstützt wird. Also habe ich testweise alle Startabbilder und Installationsabbilder durch die vom Server 2019 ersetzt. Auch dort das gleiche Problem. Habt ihr eine Idee? Im Netz gibts zu dem Fehler ein paar Infos (Skripte in der boot.wim abändern, Treiber hinzufügen, Firewall im Server abändern etc...) aber irgendwie bringt das alles nix. Zumal der Client ja eine IP vom Server kriegt, diese im DHCP Server angezeigt wird - passt für mich irgendwie nicht zum Fehler im Anhang. Wäre um Hilfe dankbar. Grüße Fabian
-
Active Directory schema extension issue if you use a Windows Server 2025 schema master role
NorbertFe antwortete auf ein Thema von testperson in: MS Exchange Forum
Danke, also eine ziemlich verweste Leiche gefunden. :) -

Active Directory schema extension issue if you use a Windows Server 2025 schema master role
MrCocktail antwortete auf ein Thema von testperson in: MS Exchange Forum
Unsere Vermutung nach Durchsicht der Historie und den Gesprächen mit den Administatoren vor Ort (und ja, die sind lange dabei ...) Start mit Server OS 2003 auf deutsch, inkl, Exchange auf deutsch AD zu dem Zeitpunkt wahrscheinlich ebenfalls auf Deutsch Ab 2007 wurden nach auf Englische OS umgestellt, das AD war 2007 noch auf einem DC 2003 Exchange 2007 wurde allerdings auf englischem OS mit englisch als Sprache installiert 2010 wurden die DCs auf 2008 geupradetet, und 2011 auf 2008R2, wahrscheinlich beides in Englisch... Wir gehen davon aus, dass zu diesem Zeitpunkt das AD ebenfalls auf ENG umgestellt wurde, da in deren "Regelwerk" steht, dass bei Schema Updates immer mindestens ein DC ausgestellt sein muss, vermuten wir, dass es dort zu Problemen gekommen sein wird, kann uns aber keiner der Admins bestätigen... Wieso es erst jetzt bei der Umstellung auf ExchangeSE aufgefallen ist, liegt wahrscheinlich dadran, dass wir einen Installationsaccount gebaut haben welcher nicht in beiden Gruppen war und daher die Prüfungen immer wieder gegen die Wand gelaufen sind. Wir haben alle DE Gruppen bereinigt und gelöscht (zusammen mit MS...), seit dem sind uns dort keine Probleme mehr untergekommen. -
Active Directory schema extension issue if you use a Windows Server 2025 schema master role
NorbertFe antwortete auf ein Thema von testperson in: MS Exchange Forum
Ich wills ja nicht nachstellen, sondern nur verstehen, wie man sowas hinbekommt. ;) -

Active Directory schema extension issue if you use a Windows Server 2025 schema master role
cj_berlin antwortete auf ein Thema von testperson in: MS Exchange Forum
Das ist nichts, was man in einer intakten Umgebung nachstellen könnte. -
Active Directory schema extension issue if you use a Windows Server 2025 schema master role
NorbertFe antwortete auf ein Thema von testperson in: MS Exchange Forum
Ne, der is ja im obigen Artikel recht deutlich beschrieben, wenn ich das noch in Erinnerung hab. Ich bezog mich auf den Beitrag direkt über mir. :) -
Active Directory schema extension issue if you use a Windows Server 2025 schema master role
cj_berlin antwortete auf ein Thema von testperson in: MS Exchange Forum
Für das aktuelle Ding? Ja, Server 2025 erlaubt derzeit (unabsichtlich) doppelte Attribute und Klassen im Schema beim Schema-Update, aber (sinnvollerweise) nicht bei der Replikation des Schemas... -
Active Directory schema extension issue if you use a Windows Server 2025 schema master role
NorbertFe antwortete auf ein Thema von testperson in: MS Exchange Forum
Gab’s da einen bekannten Auslöser für? Ist ja immer ganz gut zu wissen, wie solche Fehler entstanden sind. -
Active Directory schema extension issue if you use a Windows Server 2025 schema master role
MrCocktail antwortete auf ein Thema von testperson in: MS Exchange Forum
Ja .... Gerade erst im letzten Jahr wieder gesehen, dass es die Gruppe Administratoren und Administrators gab, beide mit der gleichen OID.... Kein Wunder dass die Probleme hatten. Es waren auch weitere Gruppen doppelt vorhanden. - Letzte Woche
-
Active Directory schema extension issue if you use a Windows Server 2025 schema master role
cj_berlin antwortete auf ein Thema von testperson in: MS Exchange Forum
Klar wird das funktionieren. Schön ist sowas nicht, aber doppelte OIDs z.B. sind auch früher schon aufgetreten...