

falkebo
-
Gesamte Inhalte
116 -
Registriert seit
-
Letzter Besuch
Beiträge erstellt von falkebo
-
-
vor 2 Stunden schrieb daabm:
Vor allem vermeidest Du damit, daß Änderungen per secpol.msc lokal auf dem DC Einzug in Deine PW-Richtlinien finden.
Warum auch immer man das vorhaben sollte

-
vor 2 Stunden schrieb dataKEKS:
Du meinst shared NIC? Habe ich mal gelernt das nur als Notlösung anzusehen ist, darum ja die Frage...
Was meinst du mit "shared NIC"?
Warum sollte das eine Notlösung sein?
Du aggregierst die NICs zu insgesamt 20GBit/s Bandbreite und erzielst damit gleichzeitig Redundanz.Ich habe mal gelernt alles was man mir erzählt zu hinterfragen ;)
-
 1
1
-
-
vor 2 Stunden schrieb Busfan:
Hallo,
ich lerne mich gerade in VLANs ein und habe da einen Knoten im Kopf...
Kann mir bitte wer wer klären wie folgende Konstellation funktioniert:
Es gibt ein Phone-VLAN100 und ein Client-VLAN200.
Vom Switch geht ein Kabel in das Phone und von dort weiter zum Client.
Meine Theorie:
Es muss am Switch ein tagged Port konfiguriert werden (VLAN 100+200).
Am Phone sind es ebenfalls tagged Ports und am 2. Port muss VLAN200 eingetragen werden.
Danke...
Meine Theorie:
Auf dem Switch sind dynamische VLANs konfiguriert welche die Frames an den entsprechenden Ports auf Basis ihrer MAC Adresse in das VOIP VLAN schieben.
-
vor 21 Minuten schrieb FragenderFrager:
unter nur surfen verstehe ich www surfen. und nicht das Daten von Extern kopiert werden können (wie bei TeamViewer möglich).
Wenn das geht kann ja jeder von außen Daten kopieren mit einem Trojaner welcher wie Teamviewer funktioniert?
wie unterbinde ich das?
Das Problem ist Teamviewer arbeitet nicht so wie du es dir vorstellst.
Für Teamviewer wird kein Portforwarding benötigt da es eine Verbindung von innen nach außen (zu den TV Servern) aufbaut.
Ein Client greift dann über die Teamviewerserver auf diesen Kanal zu und verbindet sich dann auf dein Zielsystem.Das ist eine allgemeines TCP/IP "Problem".
Du kannst mit einer Firewall die Teamviewer Server sperren, jedoch nicht ohne größeren Aufwand das Grundproblem lösen. -
vor 20 Stunden schrieb v-rtc:
Es geht um eine Sicherung einer VM . Sorry falls das missverstanden wurde.
Moin @v-rtc,
hast du es mal damit probiert:
ZitatAll user accounts used for guest processing must have the following permissions:
Logon as a batch job granted
Deny logon as a batch job not set
Diese Einstellungen kannst du per GPO ausrollen.
Ich würde einfach mal einen Domänen Benutzer erstellen, in der GPO "Logon as a batch job granted" einstellen und es testen.
Wichtig:
Für SQL Server, Domain Controller, Exchange, Oracle und Sharepoint brauchst du nochmal spezielle Berechtigungen. -
vor 7 Minuten schrieb v-rtc:
Die hatte ich schon, da steht aber nicht das was ich brauche. Als lokaler Admin tut die Veeam Sicherung. Als Sicherungs-Operator nicht.
Da steht es doch drin:
ZitatThe account used to start the Veeam Backup & Replication console must have the local Administrator permissions on the machine where the console is installed.
-
 1
1
-
-
Am 16.11.2019 um 22:18 schrieb daabm:
Alles, was da bisher steht, geht am "Problem" vorbei
")
Der FQDN und Shortname des Servers, auf den Du umleitest, muß im IE in die Intranet-Zone.
Hast du es damit probiert? @Snacky
Was ist bei raus gekommen? -
Moin @Dutch_OnE.
Meine Empfehlung: Leg dir auf jeden Fall einen Core-Switch zu.
Der kann full Modular sein oder komplett SFP+.Dann kannst du alle Access-Switche an deinen Core-Switch per LWL anbinden.
Zur Konfiguration:
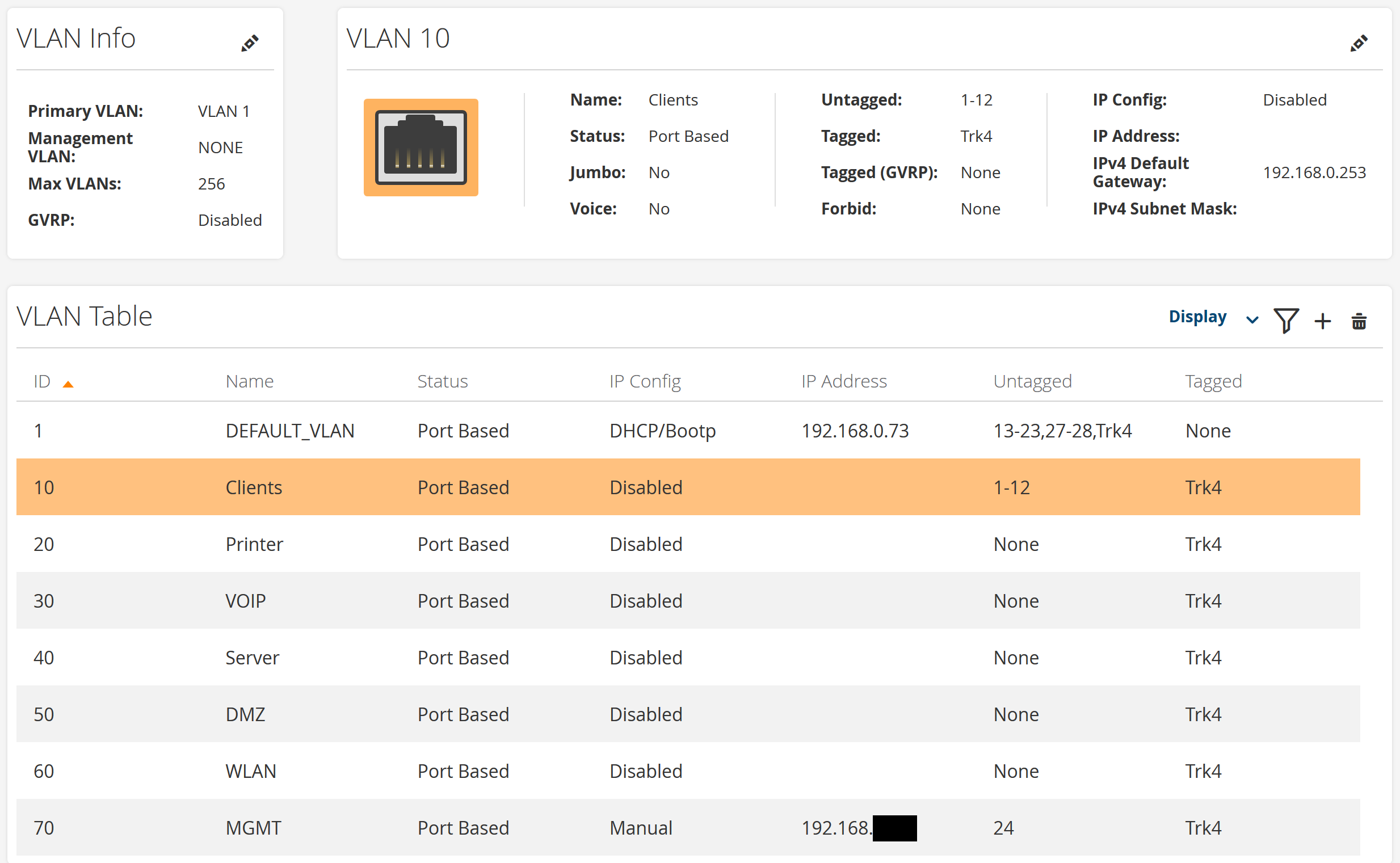
Erstelle ein neues Default VLAN z.B. auf ID 99 und setz alle nicht benutzten Ports da rein.
Erstelle 2 neue VLANs z.B. ID10 und ID20. Dann kannst du deine benötigten Ports den VLANs (untagged) zuweisen.
Erstell ein Trunk und weis dem Trunk deine SFP+ Interfaces zu (wenn gebündelt -> LACP aktivieren).
Anschließend kannst du deinem Trunk-Interface z.B. Trk1, beide VLANS (ID10 und ID20) zuweisen.

DEFAULT_VLAN nicht beachten, wird noch angepasst.
-
vor 5 Stunden schrieb Dutch_OnE:
Meine Idee ist jetzt zwischen allen Switches einen Trunk (also S1 zu S2, S2 zu S3, S3 zu S4 ...) aufzubauen und diesen dann die beiden VLANs zuzuweisen. Habe ich das soweit richtig verstanden?
Also du willst das dein ganzes Netzwerk ausfällt, wenn ein Switch in der Kette down geht?
-
Danke für dein Feedback @redvision81.
Man liest und hört immer wieder Abneigung gegen 2-Node Cluster Systeme, welche durchaus auch berechtigt sind.
Nur finde ich ist es die beste Möglichkeit (Enterprise) Hochverfügbarkeit für low Budget zu realisieren. -
vor 2 Stunden schrieb Symbadisch:
Wie wäre hier also der korrekte Zugriff?
Um vielleicht nochmal einen Denkansatz zu geben.
MS Empfehlung: Dedizierte PAW Kiste, Windows 10 Enterprise mit Credential Guard, Device Guard und Bitlocker.
Durch Security Templates mit GPOs gehärtet. -
vor 3 Minuten schrieb daabm:
Ich werf mal die Shadow Principals noch in den Raum, dann wird die Diskussion komplett wirr
Die Jungs bei MS waren auf jeden Fall kreativ beim ESAE Design

-
vor 2 Stunden schrieb Symbadisch:
Sorry, b***d ausgedrückt. Die PAW läuft nicht auf einer VM auf dem Client, sondern auf unser VMware-Umgebung.
Ich hab dir mal was passendes zu diesem Thema rausgesucht:
https://docs.microsoft.com/en-US/windows-server/identity/securing-privileged-access/privileged-access-workstations#jump-serverDas Problem in deinem Design, du verstößt gegen das "Clean Source" Prinzip.
"The clean source principle requires all security dependencies to be as trustworthy as the object being secured."In deinem Fall könnte dein Client ja kompromittiert sein. Das Risiko kann durch mehrstufige Authentifizierung am Remote PAW zwar verringert werden, ist aber immer noch da.
-
 1
1
-
-
vor 9 Stunden schrieb Symbadisch:
Nun zu meiner Frage:
- Wir melden uns auf den beiden PAWs ja direkt mit dem jeweiligen T-Admin per RDP an, wir haben also direkt Adminzugriff auf dem System. Ist das bereits falsch und kritisch bzw werden die rdp-Anmeldedaten auf unserem normalen Client gespeichert und sind somit abgfreifbar?
Das Konzept von Microsoft sieht vor dedizierte PAWs nur für administrative Aufgaben bereitzustellen.
Alternativ "darf" man eine VM in die PAW installieren um normale Office Tätigkeiten durchzuführen, nicht jedoch andersrum.Aber zu deiner Frage direkt, ja ist es.
Ist sogar eine Prüfungsfrage für die 70-744. -
vor 3 Stunden schrieb daabm:
Wir arbeiten uns grad an ESAE ab, das ist schon Herausforderung genug - aber das Grundprinzip ist da das selbe.
Und wie läufts damit? Wie weit seid ihr und wie aufwändig war das ganze bis jetzt?
-
Am 31.10.2019 um 13:06 schrieb sgn9:
Tja, Ausgangsfrage ist eben Ausgangsfrage.
Wenn deine Antwort nicht zur Ausgangsfrage passt, warum soll ich mich dann rechtfertigen?
Bist du eigentlich hier zum trollen oder was los?
Erst willst du das dir die Welt zum popeligen MCSA gratuliert, dann auf Vorschläge bzw. nett gemeinte Alternativen so antworten....
Im realen Leben gibts halt nicht nur 0 und 1.-
1
-
-
Warum möchtest du dich auf Windows Server 2019 versteifen?
Wenn du dir die Topics der Zertifizierungen anschaust, wirst du merken das es nicht mal wirklich relevant ist Windows Server 2019 dafür einzusetzen.
Und die Unterschiede zwischen Windows Server 2016 und Windows Server 2019 sind jetzt auch nicht groß. (Im Vergleich zu den anderen Sprüngen) -
Am 28.10.2019 um 15:04 schrieb sgn9:
Sooo, der MCSA 2016 ist im Sack (via 70-743)! Wie gehts weiter Richtung Server 2019?
Glückwunsch!
Nun weiter mit 70-744 und 70-413,70.414
-
Gibts ein Update @Nobbyaushb?
-
Ausnahmsweise mal spannend hier
-
Am 12.10.2019 um 21:33 schrieb NilsK:
[Phished! - michael wessel Blog]
https://www.michael-wessel.de/blog/2019/07/09/phished/Sophos Phish Threat setzen wir auch ein.
Echt sehr sehr gut um die Awareness für Mitarbeiter zu schulen. -
Wenn du den UNC Pfad über den Namen aufrufst wird standardmäßig Kerberos zur Authentifizierung verwendet, bei der IP NTLM.
Das ist der Unterschied. -
vor 33 Minuten schrieb NorbertFe:
Das schaltet den Fehler aber auch nicht aus ;) zumindest wenn ich der Description glaube.
Es tut genau das Gegenteil...
-
vor 45 Minuten schrieb Dukel:
Können die VMs zwischen den Hosts verschoben werden? Sprich ist das ein Cluster?
VMs können auch zwischen standalone Hosts live verschoben werden. (Zumindest seit Windows Server 2012)
Erfahrungen Schulungsanbieter Firebrand
in Off Topic
Geschrieben
Ich war die letzten 2 Jahre bei Firebrand und kann nur für mich und meine Kollegen sprechen.
Firebrand ist super, wenn es schnell zur Zertifizierung gehen soll (ich hab bei 6 Prüfungen eine 100% Quote).
Was mir jedoch etwas gefehlt hat, war der Bezug der Lerninhalte zur Praxis. Aber das ist meiner Meinung nach kein Problem von Firebrand, so sind nun mal die MS Zertifizierungen aufgebaut -> nicht Praxisorientiert.
Der Lernaufwand variiert. Ich hab persönlich mindestens noch nach einem 10-12h Tag, 2-4h zum Wiederholen und vorbereiten auf die Prüfung drauf gepackt.
Die Trainer waren bisher immer sehr kompetent und nicht vergleichbar mit irgendwelchen Uni Professoren die Abseits davon noch nie etwas aus der Praxis gesehen haben.
Wenn ich das rückblickend betrachte:
- Ich habe die Zertifizierung erreicht (welches das ursprüngliche Ziel war)
- Durch die Zertifizierung habe ich eine gute Grundlage für weitere Projekte geschaffen