illumina7
-
Gesamte Inhalte
42 -
Registriert seit
-
Letzter Besuch
Letzte Besucher des Profils





Fortschritt von illumina7
")





-
RDP File signieren klappt nicht richtig?
illumina7 hat einem Thema erstellt in: Windows Server Forum
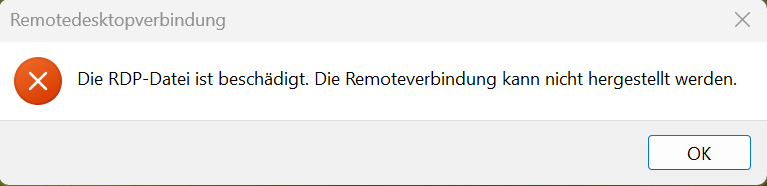
Moin zusammen, ich möchte gerne die RDP Verbindungsfiles zu unserer RDSH Farm signieren. Der Vorgang ist klar über die PS mit "rdpsign", das läuft auch durch und signiert meine RDP File erfolgreich. Jetzt kommt der spannende Teil: kopiere ich die RDP Datei auf einen Client (Win10/11), dann lässt sich damit keine Verbindung herstellen, ich sehe nur folgende Meldung: Auf den Servern der Farm lässt sich die Datei aber ausführen und damit Verbinden. Getestet auf einem Test-RDSH zur Produktiv-Farm und vom Verbindungsbroker. Jemand eine Idee woran das liegen könnte oder wo ich einen Fehler mache? Danke und Gruß illuminat
-
RDSH Prozess "System" braucht wahnsinnig viel CPU Leistung
illumina7 antwortete auf ein Thema von illumina7 in: Windows Server Forum
Abend, ich konnte den Übeltäter ausfindig machen, in unserem Fall hat tatsächlich das TSFairShare von MS die Last erzeugt. Direkt nach Setzen des keys: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\TSFairShare\Disk auf 0 ist der System-Prozess auf 0,1% abgefallen (vorher ~30-35%). Ausfindig machen konnte ich das dank dieser Anleitung: https://superuser.com/questions/527401/troubleshoot-high-cpu-usage-by-the-system-process Ist damit gelöst! Schönen Abend. -
RDSH Prozess "System" braucht wahnsinnig viel CPU Leistung
illumina7 hat einem Thema erstellt in: Windows Server Forum
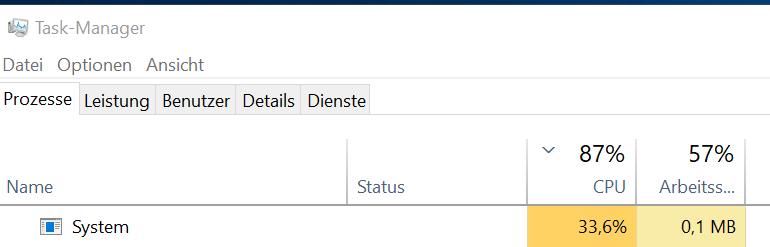
Moin, einige unserer RDSH verhalten sich seit ein paar Tagen merkwürdig und ich habe keine Idee wo das herkommen kann. Der Prozess "System" brauch irrsinnig viel CPU Leistung: Was uns aufgefallen ist, je mehr MS Office (2019 Std) Anwendungen geöffnet sind, desto höher steigt der Prozess, das scheint wohl irgendwie einen Zusammenhang zu haben. Was wir bis jetzt (erfolglos) versucht haben: - klassisch sfc /scannow - Malwarescan - alle Anwendungen deinstalliert, die Office Plugins haben - Office Reperaturinstallation bzw auch komplett deinstalliert, removal tool und neu installiert - Updates eingespielt für alle Anwendungen und OS - Defender deaktiviert - Windwos Search deaktviert - Chkdsk - Guest-Tools und Treiber neu installiert - VM gelöscht und aus Backup neu eingespielt - auf anderen host verschoben - kein Unterschied - natürlich Logfile gelesen, ProcessExplorere und Ressourcenmanager durchforstet, nichts finden können, ProcessExplorer kann keinen Dump erstellen, der uns evtl. weiterhelfen könnte Der nächste Schritt wäre dann einen RDSH komplett neu aufzusetzen und zu beobachten wie der sich verhält. Jemand eine Idee? Steckbrief zum System: Server 2019 Datacenter mit Office 2019 Std in einer RDP-Farm über Broker für Loadblancing und Management mit derzeit User Profile Disks. Nur 3 von 7 RDSH zeigen das Verhalten, alle in einer Farm, die Konfiguration zu den anderen 4 ist allerdings sehr ähnlich. Achja alles virtualisiert auf zwei proxmox Hosts, die VMs haben alle die gleichen Ressourcen und gleichen Konfigs, denke nicht, dass das eine Rolle spielt. Gruß illumina7
-
Schlechte Perfomance virtuelle RDSH
illumina7 antwortete auf ein Thema von illumina7 in: Virtualisierung
Hi Jan, danke für deinen Denkanstoss, sowohl die FW Rules sind bereits bereinigt, als auch die Reg-Einträge gesetzt, dass diese bei Logoff gelöscht werden. Mit TS Fair Share habe ich auch schon rumgespielt, jedoch ohne spürbare Veränderungen, ist aktuell wieder aktiviert. Wir nutzen Defender, Regeln werden per GPO verteilt, UPDs und deren UNC Pfade sind alle als Ausnahme definiert (inkl. noch einiger weiteren Pfade). @cj_berlin Danke für deinen Tipp zum Problem eingrenzen, ich werde da heute Abend direkt mal loslegen, ich werde auch mal direkt einen leeren 2016er mit einem leeren 2019er RDSH vergleichen. Generell kann ich nichts schlechtes zu 2019 sagen, allerdings hatten wir durchaus das ein oder andere Performance Problem bei vielen kleinen Files über SMB, das erst nach etlichen Anpassungen anständig läuft, das betraf aber ausschließlich die Fileserver und nicht die RDSH. Gruß -
Schlechte Perfomance virtuelle RDSH
illumina7 antwortete auf ein Thema von illumina7 in: Virtualisierung
Danke für deine Antwort, steht alles auf Max Performance, BIOS der Hosts halte ich auch immer aktuell. Zum Gegentesten hatte ich auch mal BIOS auf defaults zurückgestellt, ohne spürbaren Unterschied zu alles auf Max und C-States deaktiviert etc. Edit: was auch gegen die Energieoptionen spricht: alle anderen VMs rennen ja, also es steht alles auf Höchstleistung und im BIOS alles mögliche an Energiesparoptionen abgeschaltet. Alles Server 2019 Datacenter übrigens, aktuell durchgepatcht. Was micht stutzig macht, dass der Fehler unter Hyper-V und proxmox identisch ist (habe kürzlich die Plattform migriert, weil wir mit Hyper-V aus diversen Gründen unzufrieden waren). Jetzt könnte man meinen es liegt an den RDSH, die ich migriert habe, aber ich habe extra einen RDSH von 0 neu installiert (nicht geklont), der weitestgehend alles auf default stehen hat (die anderen sind optimiert), damit verhält es sich exakt gleich zu den bestehenden RDSH. Ich verstehe es einfach nicht, vielleicht teste ich das die Tage mal mit Server 2016, 2019 scheint ja insgesamt etwas "problematischer" zu sein. -
Guten Morgen zusammen, ich habe hier ein Problem mit unseren virtuellen RDSH Server, in der Anzahl insgesamt 7 Stück für je 10-15 User, meistens eher bei Richtung 10 User. Sowohl unter Hyper-V als auch unter proxmox muss ich wahnsinnig viele vCPUs zuweisen, damit die überhaupt halbwegs gut laufen, die Performance ist trotzdem nicht der Hit. Mit 4 vCPUs (was so eine gängige Empfehlung bis 10 User bei Office-Workload ist) brauche ich überhaupt nicht anfangen, schon mit einem User habe ich da duchgehend ~50-60% Auslastung, ohne direkt einen Prozess dafür identifizieren zu können (auch der Process Explorer zeigt mir keinen Prozess an, der die Last erzeugt). Mit 8 VCPUs wirds langsam erträglich und die "Grund"-CPU-Last fällt in den 10% Bereich im Leerlauf (idle, nix geöffnet) ab, langsam wird der Betrieb erträglich, ist aber noch immer sehr zäh, Programme starten mit spürbarer Verzögerung, scrollen in Word hat deutliche Ruckler. Bis 6-7 User ists okay, danach wird das komplette System so träge, dass eigentlich kaum noch zu Arbeiten ist, Anwendungen haben wahnsinnig lange Wartezeiten beim Starten, teilweise bis zu 30s. 12 vCPUs unverändert zu 8, ab 16 vCPUs läuft es dann wie es soll, alles schön schnell und geschmeidig, scrollen ruckelt nicht, im idle liegt die last bei 1-3%, auch bis 15 User ists jetzt kein Problem zu arbeiten, falls einer der anderen RDSH mal offline ist, gehen hier auch bis zu 20 Sessions relativ problemlos, dann liegen wir aber schon bei dauerhaften 80-90% Auslastung auf 16 vCores. Mehr zuweisen bringt dann keine Veränderung mehr. Gleichzeitig habe ich VMs mit 1 oder 2 vCPUs, Fileserver, Domaincontroller, Webserver, etc, die rennen mit den wenigen zugewiesenen vCPUs wie verrückt, absolut kein Vergleich zu den RDSH. Da kann ich mit einem vCPU ein FHD Video im Firefox abspielen und das läuft selbst über RDP fast ruckelfrei, an den RDSH brauch ich mit mit einer vCPU nicht mal als lokaler Admin anmelden, durchgehend 100% CPU Auslastung, ständige Disconnects. Ach ja die Host: Supermicro Server, Dual Socket AMD Epyc 7302 (16C/32T, 3,3Ghz), jeweils 384GB Ram, je 12 SSDs, 2 im Raid1 für proxmox, 10 im Raid-Z2 für den ZFS Pool. Raid-Z2 Benchmark liegt am Speicherbandbreitenlimit von PCIe3.0, die Maschinen rennen prinzipiell. Sowohl unter Hyper-V als unter proxmox verhalten sich die RDS identisch bescheiden, ob ich Numa aktiviere oder nicht macht auch keinen Unterschied. Hat jemand eine Idee, warum die RDSH bis zu unbedienbarkeit langsam werden, bzw erst ab extrem vielen Ressourcenzuweisung überhaupt benutzbar werden? Danke und Gruß
-
RemoteApp auf Terminalserver Dateitypenzuordnung
illumina7 antwortete auf ein Thema von illumina7 in: Windows Server Forum
Ich habe erfolgreich dieses PS Script getestet und bereits in unsere Produktivumgebung eingepflegt: https://www.cyberdrain.com/adding-remote-app-file-associations-via-powershell/ Damit lassen sich einzelne Dateitypen auf den RDSH an RemoteApps zuweisen - funktioniert 1A! -
RemoteApp auf Terminalserver Dateitypenzuordnung
illumina7 hat einem Thema erstellt in: Windows Server Forum
Mahlzeit zusammen, ich habe eine Frage zu RemoteApps innerhalb einer RDP-Session. Bei manchen Anwendungen wie z.B. Photoshop oder Acrobat Pro macht es Sinn diese außerhalb der RDS-Farm über einen extra RemoteApp Server zu starten. Leider kann ich jetzt innerhalb der Terminalserver die RemoteApp nicht als Standard für z.B. *.pdf Dateien zuordnen. Die User müssen die App starten und über Datei öffnen zum Pfad der Datei navigieren um diese dann mit Acrobat Pro zu öffnen. Schöner wäre es natürlich wenn das direkt bei den Usern einstellbar wäre. Unter Windows 10/11 kann ich solche RemoteApps als Standard-Dateityp-Anwendung festlegen, auf einem Terminalserver leider nicht. Zumindest ist das offiziell von MS nicht vorgesehen/supportet. Jetzt meine Frage: Gibt es irgendwie die Möglickeit, durch einen Registry Tweak o.ä., die MS Vorgabe zu Umgehen und auch auf einem Terminalserver eine RemoteApp Dateitypen als default zuordnen zu können? Vielleicht war jemand schon mal vor einem ähnlichen Problem gestanden. Gruß illumina7 -
RD Farm meldet sich nach und nach ab
illumina7 antwortete auf ein Thema von illumina7 in: Windows Server Forum
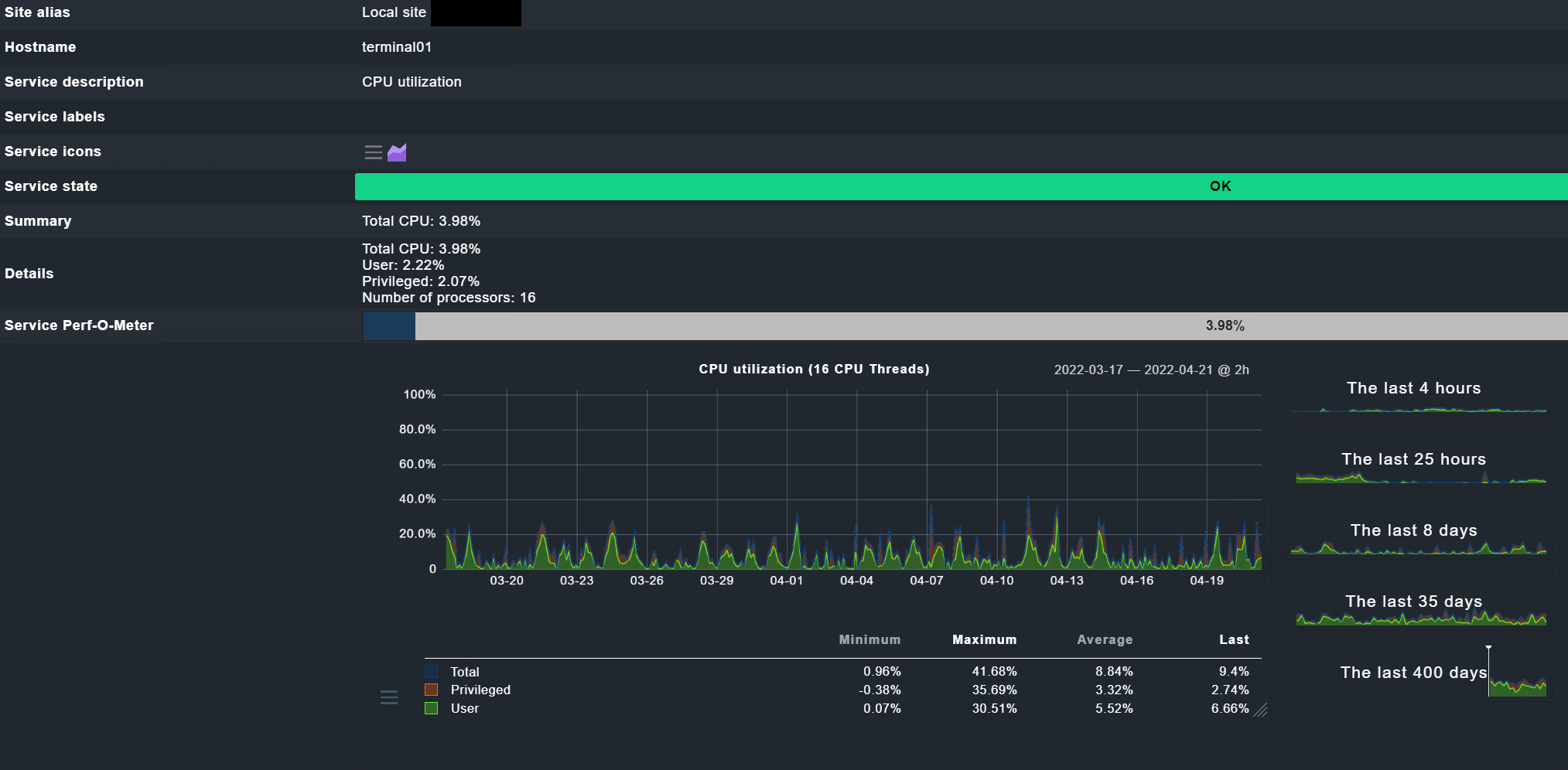
Das ist die CPU Auslastung über die letzten 35 Tage, exemplarisch an einem der RDSH, erfasst über checkmk: Websites sind bei uns reguliert über pfblockerNG, d.h. Browsergames sind eher unwahrscheinlich. PS: ich habe vielleicht die Ursache bzw. das Problem gefunden, aktuell bin ich noch am Testen an einem RDSH, den ich dafür aus dem Produktivbetrieb entfernt hab. Aktuell 10 Tage ohne UPD Disconnect (und ohne Reboot). Ab kommenden Montag schalte ich diesen wieder in den Produktivbetrieb und beobachte weiter. Wenn der Fehler wirklich behoben sein sollte, dann werde ich das hier auch ausführlich beschreiben.
-
RD Farm meldet sich nach und nach ab
illumina7 antwortete auf ein Thema von illumina7 in: Windows Server Forum
Habe ich inzwischen auch einstellt, aber der Fehler tritt ja meistens während der Arbeitszeit auf, ändert also leider nichts am Kernproblem. -
RD Farm meldet sich nach und nach ab
illumina7 antwortete auf ein Thema von illumina7 in: Windows Server Forum
Hab schon verstanden auf was du hinaus wolltest bezühlich Arbeitsspeicher im Standby, ich werde das mal weiter beobachten, wie sich das so im Laufe des Tages verhält. Die RDSH VMs stürzen halt nicht im eigentlichen Sinn ab, sondern trennen die Verbindungen zur den User Profile Disks, die auf einem Fileserver liegen. Gibt keinen BSOD oder sonst einen aufschlussreichen Logeintrag. Ich werde mal bei einer VM den daily Reboot pausieren und mir den Ram anschauen, wenn die Sessions getrennt sind. Remote-Apps auf Terminalserver sind halt nur bedingt gut nutzbar, da ich die innerhalb der RDSH nicht als default-Anwendung festlegen kann (anders als auf einer Workstation, wo das funktioniert). D.h. Office z.B. kann ich nicht als Remote-App nutzen. Derzeit sind Anwendungen als Remote-App ausgelagert wie Acrobat Pro oder ein CAD Programm, Energieberater, etc., die nur einige wenige User nutzen. Ich sehe aber dass die Citrix Workspace-App viel Ram im Standby reserviert ggf. kann ich die in eine Remoteapp auslagern, das muss ich aber erst mal Testen. -
RD Farm meldet sich nach und nach ab
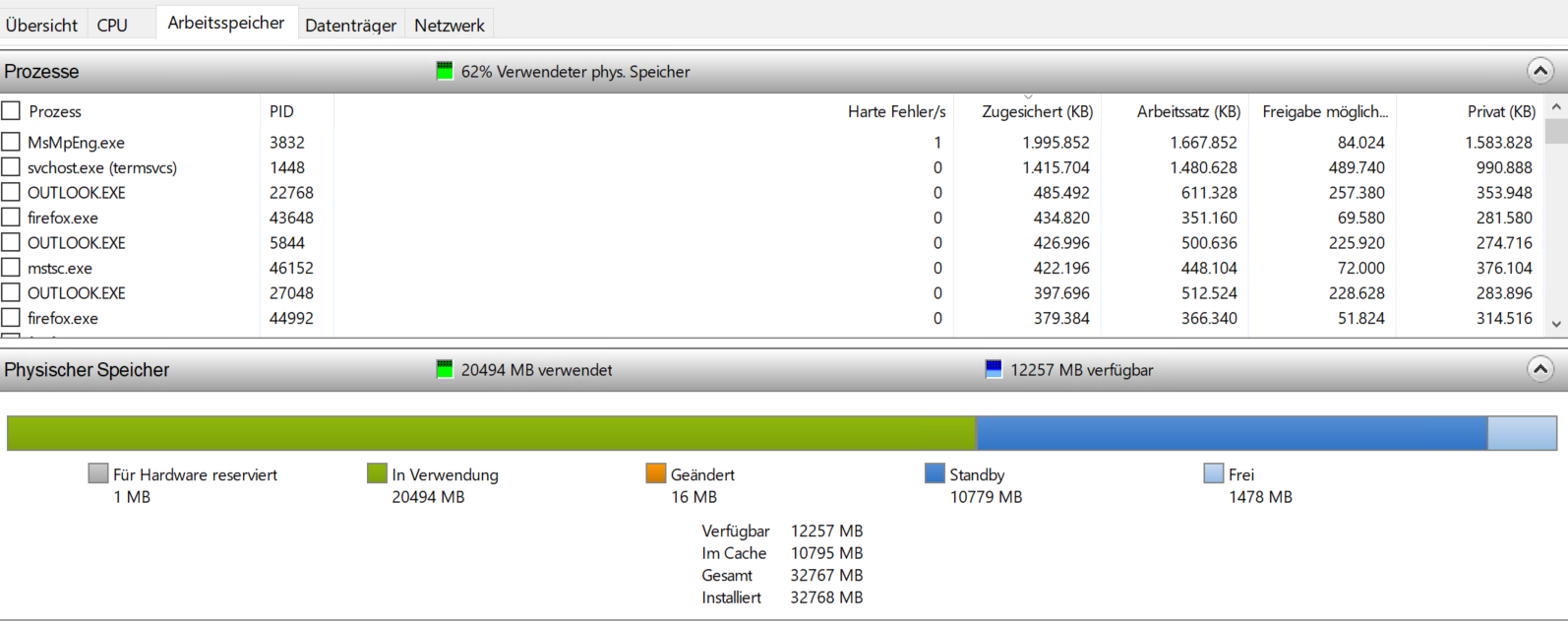
illumina7 antwortete auf ein Thema von illumina7 in: Windows Server Forum
Moin @Weingeist sorry für die späte Anwort, aber war die letzten Wochen privat voll eingespannt und hatte absolut keine Zeit nebenher (Hauskauf und Sanierung :D). So sieht jetzt aktuell der Ressourcenmonitor eines RDSH aus: Überbuchung habe ich aktuell tatsächlich keine, Zuweisung ist derzeit vCPUs 1:1 (obwohl unter Hyper-v 1:2 bis 1:4 kein Problem sein sollte; hab auch gelesen, dass bis 1:8 möglich ist, aber vom Workload abhängig, ohne jetzt eigene Erfahrungen damit zu haben), Ram ist bei zwei RDSH exklusiv und bei 2 weiteren dynamisch (aber limitiert), hatte ich zwischenzeitlich aber auch mehrfach umgestellt. Selbst wenn der Ram in den VMs bis ans Limit belegt wird, gibts aber noch keine Überbuchung und die Hosts haben noch ca. 10% Reserve Ram zur Verfügung (also ca. 38GB pro Host). Verschoben hab ich die VMs schon in alle Richtungen. Storage geändert, Hosts getauscht, alles auf einem Host usw., da der Fehler immer sehr schnell auftritt (1-7 Tage Laufzeit der RDSH VMs), weiß ich auch sehr schnell ob sich was geändert hat. Durch die täglichen Reboots der RDSH ist der Fehler aktuell nicht mehr aufgetreten, Idealzustand ist das allerdings nicht. Über Reddit habe ich zufällig noch einen andern Sysadmin gefunden, der exakt das gleiche Problem in seiner RDSH Farm hat, die aber vorher 2 Jahre fehlerfrei lief. Wir stehen auch im Austausch, vielleicht können wir gemeinsam den Fehler eingrenzen.
-
RD Farm meldet sich nach und nach ab
illumina7 antwortete auf ein Thema von illumina7 in: Windows Server Forum
Aus dem Grund läuft ja ein Teil der Programme als Remoteapp über einen extra Server, aber ich verstehe deinen Punkt. Nur frisst bei uns auch nichts den Arbeitsspeicher auf, im Gegenteil, der ist eigentlich selbst wenn 20-25 User auf einer Maschine arbeiten weit vom zugeteilten Maximum entfernt. Zum Thema Nutzerprofil: die User arbeiten derzeit querbeet über alle 4 RDSH und die Profile sind per User Profile Disks auf einem virtuellen Fileserver abgelegt. Ist tatsächlich eine ISO aus dem VLSC, allerdings sind damit alle Hosts und VMs installiert und "nur" 3 von 4 RDSH machen die Probleme, alles andere läuft ohne Auffälligkeiten. Das letzte Mal als ich ein Ticket bei MS aufgemacht hatte, verlief das auch nach einigen Wochen im Sand, eine Möglichkeit wäre es aber schon noch. -
RD Farm meldet sich nach und nach ab
illumina7 antwortete auf ein Thema von illumina7 in: Windows Server Forum
Zwei identisch ausgestattete Supermicro Server (Dual AMD Epyc, 384GB DDR4 ECC, 2xRaid10 Intel Server SSDs) als Hyper-V Hosts, Maschinen sind für Hyper-V zertifiziert. Server 2019 Datacenter in der kompletten Umgebung (Hosts und VMs, RDSH, Fileserver, etc.). Eine RDSH VM hat derzeit 16 vCPUs und 32-48GB Ram zugewiesen, Broker und Lizenzserver laufen auf eigener VM getrennt, insgesamt ca. 120 User, VMs laufen ziemlich entspannt, seitdem ich die vCPUs von 8 auf 16 verdoppelt habe. Alle VMs werden repliziert, dafür sind die beiden Server direkt per 2x10Gbit/s LWL Kabel verbunden (Intel X710, nur für Replikation). Beide Hyper-V Hosts haben je zwei Intel X550 10Gbit Kupfer NICs Onboard verbaut, über die diese im Teaming am Netzwerk hängen. Gepatcht sind die beiden Hosts derzeit auf einen Netgear XS708T als "Core Switch", dort sind die 4 weiteren internen 1G HPE Switches für die Clients gepatcht. Klingt wirklich unserem Problem sehr ähnlich. Unsere Software auf den RDSHs: Office 2019 Std, Firefox ESR, Acrobat Reader, 7-zip, CTI (MyPortal), Citrix Client für Buchhaltungssoftware, sfirm, pdf24, Zoom und Teams, Nextcloud Client. Alles andere an "Spezial-Software" läuft als Remoteapp über einen eigenen Server (z.B. Acrobat Pro, CAD Software, etc.). -
RD Farm meldet sich nach und nach ab
illumina7 antwortete auf ein Thema von illumina7 in: Windows Server Forum
Die Analyse hatte ich schon einige Zeit aktiviert - ohne hilfreiches Ergebnis. Protokolle der Hyper-V Hosts sind praktisch komplett sauber, überhaupt nichts Auffälliges. Alle 5 RDSH Server sind mit der identischen Software ausgestattet (gleiche Installer) und komplett durchgepatcht. 4 RDSH sind produktiv, 3 hängen sich ab einer nicht, der 5. RDSH ist ein Testserver, der hängt sich auch nicht ab. Die Server sind nicht geklont sondern wirklich einzeln installiert. Denke nicht, dass der Fehler von irgendeiner ominösen Software ausgelöst wird, dann müsste es ja eigentlich alle 4 RDSH betreffen. Nachträglich hatte ich noch den Switch, an dem die beiden Hosts hängen, getauscht, leider auch erfolglos. Beim Switchtausch ist mir aufgefallen, dass ein kurzer Netzwerkdisconnect eben nicht zum "Verlieren" der User Profile Disks führt. Erste bei einer Trennung von ~10min waren die UPD dann komplett abgehängt, also selbst ein paar verlorene Datenpakete sind kein Indikator für eine Trennung. Problem tritt mit und ohne NIC Teaming auf dem Hyper-V Host auf, aktuell ist das Teaming aber wieder aktiv. Irgendwie müsste ich den ursprünglichen Fehler finden, auf dem hin dann alle Windows Protokolle der RDSH mit Fehlermeldungen zugespamt werden. Trotz etlicher Tage Logs lesen und analysieren ist es mir bis jetzt noch nicht gelungen diesen einen Fehler zu identifizieren. Zusätzlich erschwert wird die Fehlersuche auch durch die Symptome, ich kann einen "abgehängten" RDSH am Broker nicht mehr zum Login deaktivieren und mich in Ruhe durch die Logs wühlen, der Broker versucht also weiterhin neue User auf den Server zu verbinden und die User in ihre getrennten Sitzungen zurück zu verbinden, was nicht funktioniert. Einen fixen Zeitpunkt gibt es auch nicht, der Fehler tritt idR zwischen 1 und 7 Tage Laufzeit auf, aber auch nicht immer, teilweise erst nach 4 Wochen auf einem Server, während ich die anderen beide 3mal die Woche neustarten musste. Also bin komplett ratlos inzwischen.