Spackenheimer
-
Gesamte Inhalte
22 -
Registriert seit
-
Letzter Besuch
Fortschritt von Spackenheimer
")





-
Öffentlicher Ordner - Fehler bei Berechtigung von "Senden als"
Spackenheimer antwortete auf ein Thema von Spackenheimer in: MS Exchange Forum
So, es gibt neue Erkenntnisse: Beim Setzen der Berechtigung "Senden als" beim öffentlichen Ordner über das ECP schlägt ja folgender Befehl fehl: Add-ADPermission -Identity 'FIRMA.local/Microsoft Exchange System Objects/Zentrale' -User '9744ad25-4677-446d-b48b-8b037b6d74b6' -AccessRights 'ExtendedRight' -ExtendedRights 'send as' Wenn ich Befehl kopiere, die SID/GUID durch den Benutzernamen ersetze und direkt in der Powershell ausführe funktioniert es. Also gibt es an irgendeiner Stelle einen Fehler beim Auflösen Benutzername<>GUID. Seltsamerweise funktioniert die Übersetzung ja aber in dem Fehlerdialog (Beitrag #2) wieder, dort wird der Benutzername angezeigt. Ich betreue noch zwei weitere Exchange 2016 Server, identischer Patchstand. Bei dem einen tritt der Fehler auch auf, bei dem anderen nicht. Könnt ihr das bei euch mal checken? -
Öffentlicher Ordner - Fehler bei Berechtigung von "Senden als"
Spackenheimer antwortete auf ein Thema von Spackenheimer in: MS Exchange Forum
Das hat nix gebracht... :/ -
Öffentlicher Ordner - Fehler bei Berechtigung von "Senden als"
Spackenheimer antwortete auf ein Thema von Spackenheimer in: MS Exchange Forum
Hier hat jemand bei derselben Fehlermeldung das Discovery Suchpostfach im Verdacht... Das werde ich heute Abend mal testen und neu anlegen. -
Öffentlicher Ordner - Fehler bei Berechtigung von "Senden als"
Spackenheimer antwortete auf ein Thema von Spackenheimer in: MS Exchange Forum
Das ist die SID des Kontos, das ich im Beispiel hinzufügen wollte. -
Öffentlicher Ordner - Fehler bei Berechtigung von "Senden als"
Spackenheimer antwortete auf ein Thema von Spackenheimer in: MS Exchange Forum
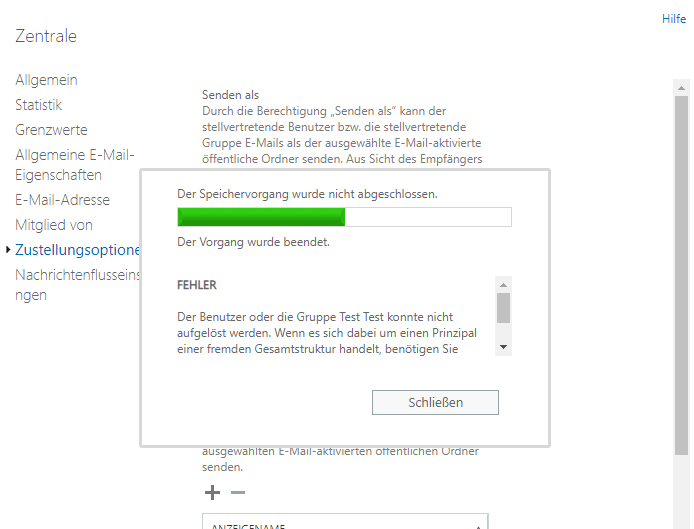
Hierzu hat wohl niemand eine Idee? Der Fehler sieht im ECP übrigens folgendermaßen aus: Die Befehlsprotokollierung gibt es folgendermaßen aus:
-
Öffentlicher Ordner - Fehler bei Berechtigung von "Senden als"
Spackenheimer hat einem Thema erstellt in: MS Exchange Forum
Hallo liebes Forum, wir haben hier einen Fehler bei einem Exchange 2013. Wenn ich bei einem e-mail aktivierten öffentlichen Ordner ein Benutzerkonto bei "Senden als" oder "Senden im Auftrag" berechtigen (oder das Recht entziehen) will bekomme ich folgende Fehlermeldung: "Der Benutzer oder die Gruppe Mustermann konnte nicht aufgelöst werden. Wenn es sich dabei um einen Prinzipal einer fremden Gesamtstruktur handelt, benötigen Sie entweder eine birektionale oder eine ausgehende Vertrauensstellung." Fehlermeldung lautet auf Englisch "Couldn't resolve the user of group "Mustermann." If the user or group is a foreign forest principal, you must have eighter a two-way trust or an outgoing trust." Ich würde die Meldung selbst erstmal als irreführend einstufen: Es gibt zwar eine Vertrauensstellung zu einer anderen Domäne, es lassen sich aber auch keine Konten aus derselben Domäne hinzufügen, in der der Exchange steht. Ich kann das Recht "Senden als" jedoch z.B. bei Postfächern setzen, auch für Benutzer aus der jeweils anderen vertrauten Domäne und es gibt auch sonst keine Probleme, daher sollte mit der Vertrauensstellung alles i.O. sein. Habe das Netz schon in deutsch und englisch durchsucht, finde aber niemanden mit demselben Problem. Hat jemand eine Idee? Das funktionierte definitiv bis vor kurzem und es wurde nichts wissentlich verändert. Hier noch der Eintrag aus dem Eventlog "MSExchange Management" Cmdlet fehlgeschlagen. Cmdlet Remove-ADPermission, Parameter -Identity "FIRMA.local/Microsoft Exchange System Objects/ÖffentlicherBeispielordner" -User "Max Mustermann" -ExtendedRights ("send as"). Unter Details steht folgendes: Remove-ADPermission -Identity "FIRMA.local/Microsoft Exchange System Objects/ÖffentlicherBeispielordner" -User "Max Mustermann" -ExtendedRights ("send as") FIRMA.local/Eichenzell/Benutzer/Administrator S-1-5-21-3815382074-1658224737-102353067-500 S-1-5-21-3815382074-1658224737-102353067-500 Local-ECP-Unknown 17252 w3wp#MSExchangeECPAppPool 38 00:00:00 Vollständige Gesamtstruktur anzeigen: 'True', Konfigurationsdomänencontroller: 'FIRMADC1.FIRMA.local', Bevorzugter globaler Katalog: 'FIRMADC1.FIRMA.local', Bevorzugte Domänencontroller: '{ FIRMADC1.FIRMA.local }' Microsoft.Exchange.Data.Common.LocalizedException: Der Benutzer oder die Gruppe Max Mustermann konnte nicht aufgelöst werden. Wenn es sich dabei um einen Prinzipal einer fremden Gesamtstruktur handelt, benötigen Sie entweder eine birektionale oder eine ausgehende Vertrauensstellung. ---> System.SystemException: Die Vertrauensstellung zwischen der primären Domäne und der vertrauenswürdigen Domäne konnte nicht hergestellt werden. bei System.Security.Principal.NTAccount.TranslateToSids(IdentityReferenceCollection sourceAccounts, Boolean& someFailed) bei System.Security.Principal.NTAccount.Translate(IdentityReferenceCollection sourceAccounts, Type targetType, Boolean forceSuccess) bei System.Security.Principal.NTAccount.Translate(Type targetType) bei Microsoft.Exchange.Configuration.Tasks.SecurityPrincipalIdParameter.GetUserSidAsSAMAccount(SecurityPrincipalIdParameter user, TaskErrorLoggingDelegate logError, TaskVerboseLoggingDelegate logVerbose) --- Ende der internen Ausnahmestapelüberwachung --- bei Microsoft.Exchange.Configuration.Tasks.Task.ThrowError(Exception exception, ErrorCategory errorCategory, Object target, String helpUrl) bei Microsoft.Exchange.Configuration.Tasks.Task.WriteError(Exception exception, ErrorCategory category, Object target) bei Microsoft.Exchange.Configuration.Tasks.SecurityPrincipalIdParameter.GetUserSidAsSAMAccount(SecurityPrincipalIdParameter user, TaskErrorLoggingDelegate logError, TaskVerboseLoggingDelegate logVerbose) bei Microsoft.Exchange.Configuration.Tasks.SecurityPrincipalIdParameter.GetSecurityPrincipal(IRecipientSession session, SecurityPrincipalIdParameter user, TaskErrorLoggingDelegate logError, TaskVerboseLoggingDelegate logVerbose) bei Microsoft.Exchange.Management.RecipientTasks.SetPermissionTaskBase`3.InternalValidate() bei Microsoft.Exchange.Management.RecipientTasks.SetADPermissionTaskBase.InternalValidate() bei Microsoft.Exchange.Configuration.Tasks.Task.<ProcessRecord>b__b() bei Microsoft.Exchange.Configuration.Tasks.Task.InvokeRetryableFunc(String funcName, Action func, Boolean terminatePipelineIfFailed) 7 System.SystemException: Die Vertrauensstellung zwischen der primären Domäne und der vertrauenswürdigen Domäne konnte nicht hergestellt werden. bei System.Security.Principal.NTAccount.TranslateToSids(IdentityReferenceCollection sourceAccounts, Boolean& someFailed) bei System.Security.Principal.NTAccount.Translate(IdentityReferenceCollection sourceAccounts, Type targetType, Boolean forceSuccess) bei System.Security.Principal.NTAccount.Translate(Type targetType) bei Microsoft.Exchange.Configuration.Tasks.SecurityPrincipalIdParameter.GetUserSidAsSAMAccount(SecurityPrincipalIdParameter user, TaskErrorLoggingDelegate logError, TaskVerboseLoggingDelegate logVerbose) Ex19B768 False 0 objects execution has been proxied to remote server. 0 ActivityId: aff5852d-9ea6-4b1f-8fb4-1e6f313f54de ServicePlan:;IsAdmin:True; de-DE -
Autodiscovery mit zwei Domänen mit Vertrauensstellung und gemeinsamen Exchange
Spackenheimer antwortete auf ein Thema von Spackenheimer in: Active Directory Forum
In der Tat... Das war so einfach, dass ich nicht drauf gekommen bin. :D -
Autodiscovery mit zwei Domänen mit Vertrauensstellung und gemeinsamen Exchange
Spackenheimer antwortete auf ein Thema von Spackenheimer in: Active Directory Forum
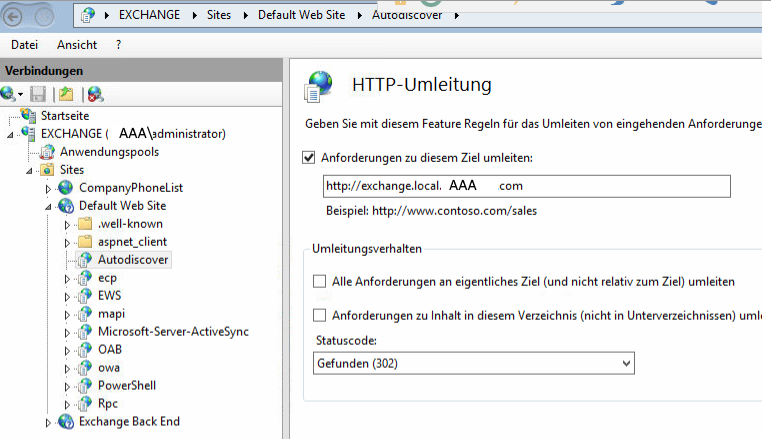
Ok, da komme ich gerade nicht weiter. Ich habe den redirect bei der Seite Autodiscover im IIS auf dem Exchange eingestellt, ändert aber nichts und führt im Gegenteil dazu, dass Autodiscover nicht mehr funzt und der Zertifikatsfehler kommt immer noch. Habe alle drei Namen die im Zertifikat stehen ausprobiert und auch mit den Haken beim Umleitungsverhalten gespielt.
-
Autodiscovery mit zwei Domänen mit Vertrauensstellung und gemeinsamen Exchange
Spackenheimer antwortete auf ein Thema von Spackenheimer in: Active Directory Forum
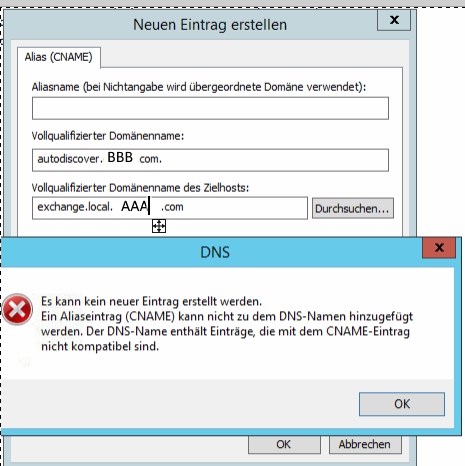
Das war ja meine Idee. Der lässt sich in der Zone autodiscover.BBB.com aber nicht ganz oben anlegen ohne einen Namen anzugeben.
-
Autodiscovery mit zwei Domänen mit Vertrauensstellung und gemeinsamen Exchange
Spackenheimer hat einem Thema erstellt in: Active Directory Forum
Moin liebes Forum, ich bin hier aktuell dabei Altlasten unseres Vorgänger-Admins zu beheben. Es handelt sich um zwei Unternehmen, welche jeweils eine eigene Domäne haben, die per Vertrauensstellung miteinander verbunden sind. Es sind .local Domänen. Es gibt einen gemeinsamen Exchange, der steht in der Domäne der Firma AAA . Die Postfächer der Firma BBBB sind als verknüpfte Postfächer angelegt. Bisher war Autodiscovery bei Firma B folgendermaßen geregelt: Es gab im DNS der BBB.local eine Zone namens BBB.com (das ist auch die Mail- und Web-Domain). Dort gab es einen _autodiscovery SRV Eintrag mit Verweis auf exchange.local.AAA.com, welcher wiederum über eine Bedingte Weiterleitung (local.AAA.com) aufgelöst wurde. Damit die MA auch auf die eigene Website kommen wurde in der Zone BBB.com ein Hosteintrag namens WWW mit der entsprechenden IP erstellt. Das ist aber unglücklich, weil so nun andere Seiten unter der Domain nicht erreichbar sind, wie z.B. die karriere.BBB.com. Da ich das nicht ständig pflegen will habe ich es folgendermaßen umgebaut: In der BBB.local eine DNS Zone autodiscover.BBB.com angelegt mit Hosteintrag der auf die IP des Exchange verweist. Damit funktioniert Autodiscovery und Outlook, allerdings kommt jedes mal ein Zertifikatsfehler (jeweils nur 1x beim Verbinden & Outlook Start, aber trotzdem unglücklich), weil das Zertifikat des Exchange ja auf die AAA.com ausgestellt ist (also mail.AAA.com und exchange.local.AAA.com). Ich bräuchte also sowas wie einen CNAME Aliaseintrag in der Zone autodiscover.BBB.com, welche in den zum Zertifikat passenden Namen übersetzt. Den kann ich aber nicht ohne Namen im root der Zone anlegen und wenn ich eine Zone mit BBB.com und autodiscover als CNAME anlege, habe ich ja wieder das Ausgangsproblem. Versteht jemand dieses Gewurschtel? :D -
Hyper-V unterschiedliche Geschwindigkeit beim Kopieren von VM zu VM
Spackenheimer antwortete auf ein Thema von Wolke2k4 in: Virtualisierung
Hatte mal ein ähnliches Fehlerbild, vielleicht hilft das ja: -
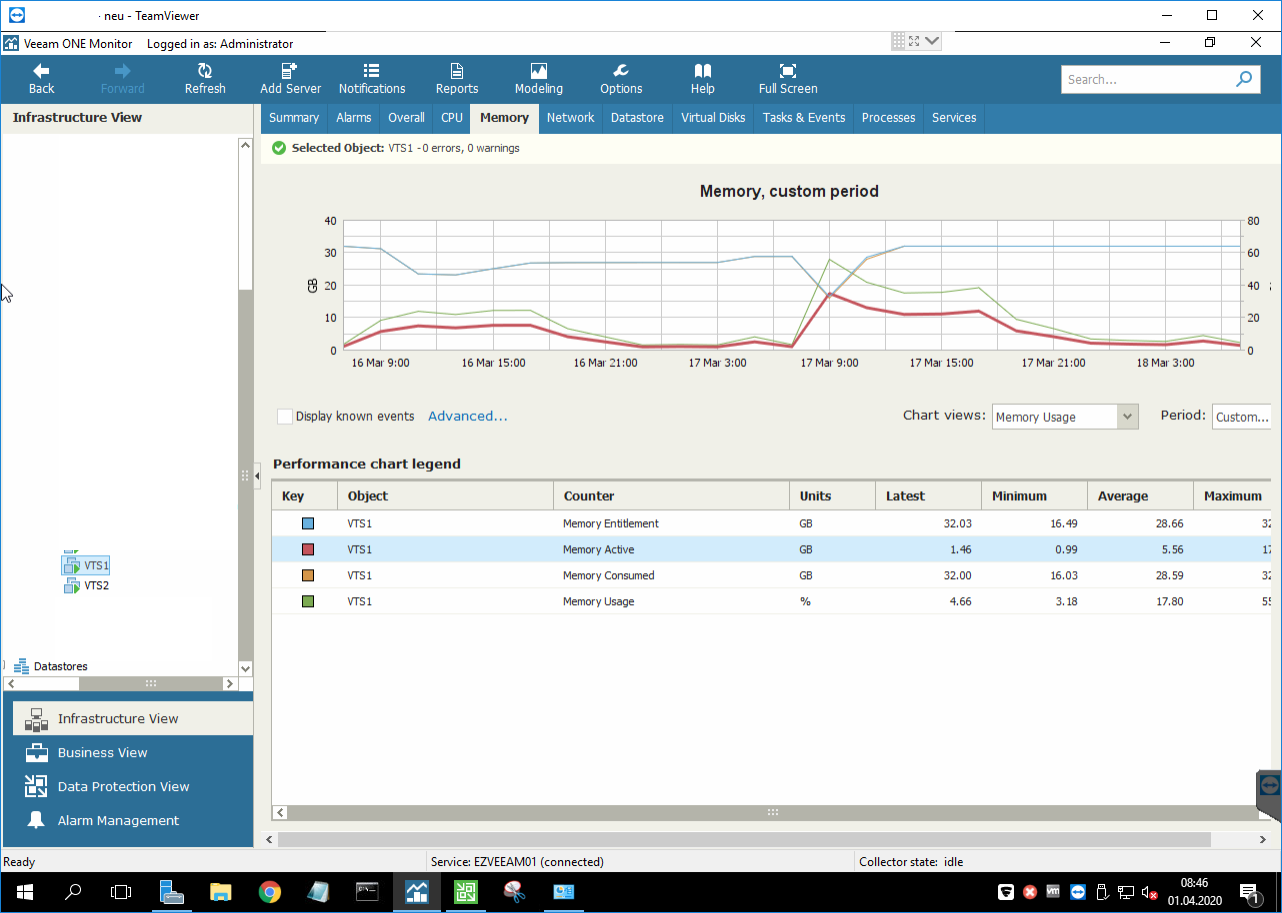
Hallo liebes Forum wir haben seit 17. März Probleme mit zwei Windows 2016 Std. VMs, die als Terminalserver im Verbund laufen, einer davon ist der Broker. Die VMs frieren nach dem Hochfaren bei der ersten Anmeldung komplett ein (auch bei einem lokalen Konto). Sie antworten dann auch nicht mehr auf Ping. In der VMware Konsole kreiselt teilweise noch der Kreis bei der Anmeldung, teilweise bewegt sich aber gar nichts. Nach Zeitraum x, meist ca. 10 Minuten, reagieren sie auf einmal wie von Geisterhand wieder, auch der Ping kommt ab dem Zeitpunkt wieder zurück. Das Verhalten zeigen sie wie es aussieht nur nach dem Boot, wenn sie durchlaufen gibt's keine Probleme. Da es ab dem 17. März auftrat und an dem Tag bzw. wahrscheinlich in der Nacht auch Updates installiert wurden, hatte ich natürlich Windows Updates im Verdacht, habe auf einen Stand von der Woche davor zurückgesichert - kein Unterschied, Fehler tritt auch ohne die Updates vom 17. März auf. Der Fehler tritt übrigens auch nicht bei jedem Boot auf! Es wirkt willkürlich. Ist-Umgebung: 3 Fujitsu ESXi Hosts welche im Cluster mit HA-Unterstützung laufen (noch unter VMware 6.0). Speicher ist ein Dell Unity das per FC angebunden ist. Der Fehler tritt nur bei diesen beiden VMs auf. Wir haben noch einen anderen 2016 Std, der zeigt das Verhalten nicht, hat aber auch nicht die aktuellsten Updates. Es wurde an den VMs nichts installiert, da hat sich seit Monaten nichts geändert. Sie wurden ursprünglich Ende 2017 installiert, waren seit Mitte 2018 im produktiven Einsatz und liefen seitdem reibungslos durch. Der Fehler tritt auf jedem Host auf. Auch wenn man die VMs komplett heruntergefahren hatte. Die Auslastung der Hosts ist nicht außergewöhnlich. Wir haben schon alle VMs heruntergefahren und die Hosts neugestartet, sie liefen seit 240 Tagen - keine Besserung. Wir haben sogar einen Ersatz-Host dort ins Netz gebracht, aktuelle und ungenutzte Hardware von vor 2 Jahren, der Datenspeicher ist ebenfalls ein anderer (per NFS von OpenE eingebunden), die Switches etc. über die er ins Netzwerk geht sind andere. Der Host (Supermicro) läuft unter VMware 6.5, wir haben die VMs also auf diesen Host zurückgesichert, auf 6.5 aktualisiert, die VMware Tools aktualisiert. Das lief die ersten 10 Neustarts dann auch, weswegen wir Kompatibilitätsprobleme mit 2016 und VMware 6.0 im Verdacht hatten - bei Tests gestern Abend trat der Fehler dort aber wieder auf. Man findet auch in keinem Log Fehler, weder im vSphere, noch in VeeamOne. Die einzige Auffälligkeit die ich dort feststellen konnte war das hier, Speichernutzung ging unter die Decke, obwohl die Maschine nichts gemacht hat. 32GB Ram, die normalerweise auch bei voller Nutzeranzahl nicht über 25GB Auslastung gehen. Zur Wiederholdung: es passierte in diesem Zeitraum auf der VM absolut nichts. Man sieht, dass es sich ab etwa 8:20 Uhr (erster Screenshot) bzw. 9 Uhr (zweiter Screenshot) wieder normalisiert hat, ab dann arbeiten die VMs als wäre nichts gewesen und bringen auch normale Performance. So langsam gehen mir die Ideen aus. Die Terminalserver neu zu installieren wollte ich mir wenn möglich ersparen, zumal ich bei meiner Recherche Beiträge gesehen habe, wo der Fehler auch nach Neuinstallationen auftrat.
-
VMware - nur 1Gbit trotz angezeigten 10Gbit
Spackenheimer antwortete auf ein Thema von Spackenheimer in: Virtualisierung
Ja, das hätte ich dazuschreiben können, zumal es im Nachhinein damit eigentlich auch offensichtlich war. :) Das Umstellen der 1Gbit auf Standby sollte im laufenden Betrieb ohne Ausfall möglich sein oder? EDIT: Mut zur Lücke - erwartungsgemäß keine Ausfälle beim Umstellen der 1Gbit Karte als standby. -
VMware - nur 1Gbit trotz angezeigten 10Gbit
Spackenheimer antwortete auf ein Thema von Spackenheimer in: Virtualisierung
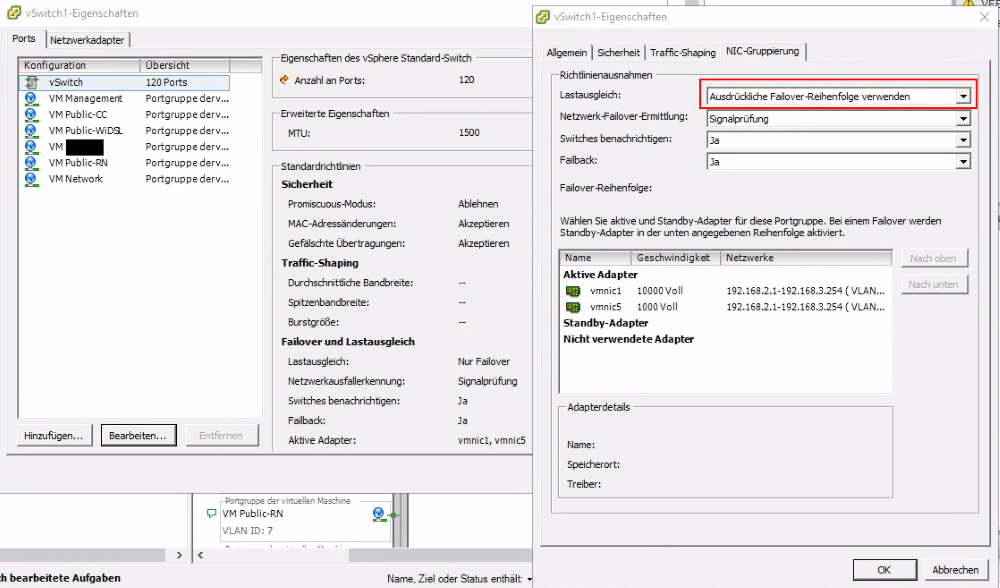
Habe es zwischenzeitlich gefunden. Die Hosts sind über zwei unterschiedliche physische NICs angebunden, die interne 1Gbit Karte und eine gesteckte 10Gbit. Der Lastausgleich der vSwitche war auf "Anhand der ursprünglichen ID des virtuellen Ports routen" gestellt. Habe auf "Ausdrückliche Failover-Reihenfolge verwenden" gestellt, damit passiert laut Doku kein Lastausgleich und da die 10Gbit Karte in der Failover-Reihenfolge oben steht wird nun nur sie genutzt. Alle vorher langsamen VMs sind nun schneller.
-
VMware - nur 1Gbit trotz angezeigten 10Gbit
Spackenheimer hat einem Thema erstellt in: Virtualisierung
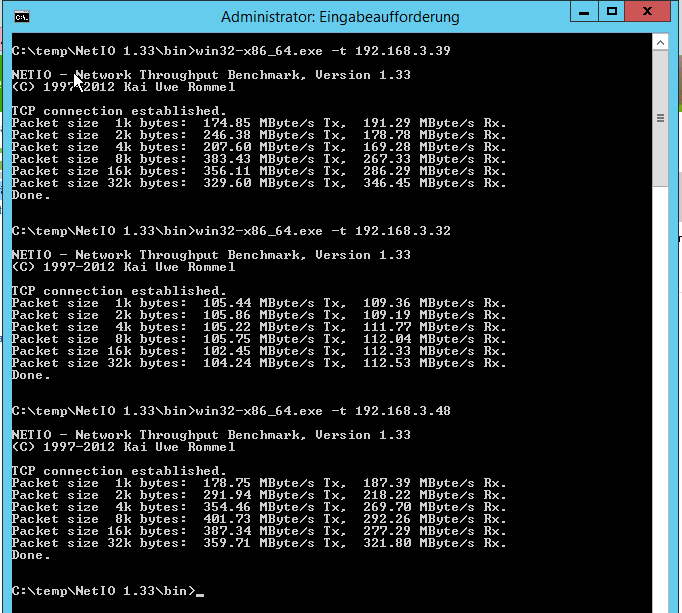
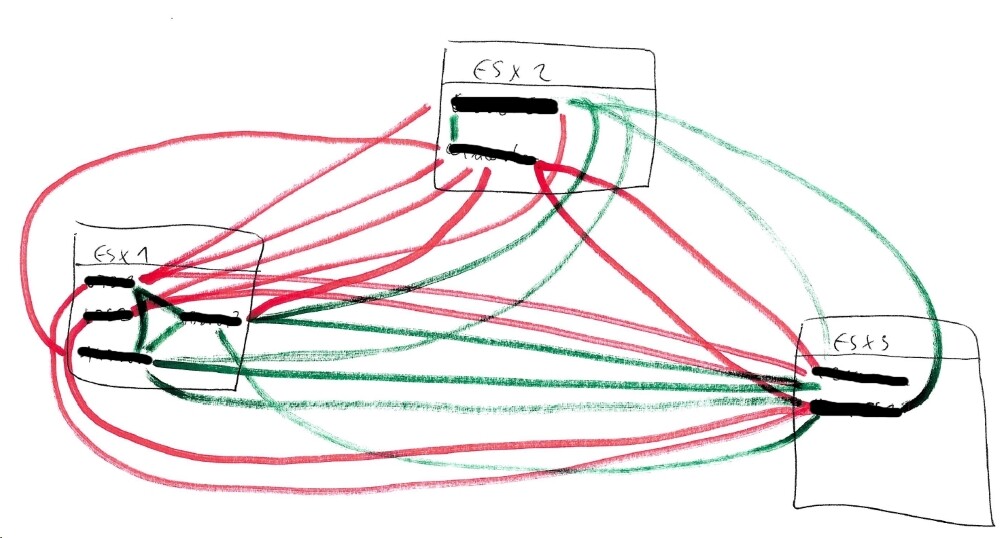
Hallo, wir setzen einen Cluster aus 3 identischen Hosts sein, auf denen insgesamt ca. 25 VMs verteilt sind (gleichmäßig verteilte Last). Die Hosts sind untereinander mit 10Gbit Karten an 10Gbit Switches mit guten Kabeln verbunden. Ich habe das Problem, dass einige VMs nur 1Gbit Geschwindigkeit bekommen, obwohl der VMXNET3 Adapter konfiguriert ist und in den Eigenschaften der Netzwerkverbindung auch 10Gbit angezeigt werden. Die VMs hängen pro Host jeweils an denselben vSwitches in denselben VM-Netzwerken. Das Problem betrifft nur einzelne VMs pro Host. Andere VMs desselben Hosts bekommen mit denen auf anderen Hosts die vollen 10Gbit, also liegt es nicht an den Hosts oder der physischen Verkabelung. Die betroffenen VMs bekommen mit anderen VMs desselben Hosts volle 10Gbit, nur eben nicht zu einem anderen Host. VM1 auf Host1 zu VM2 auf Host1: 10Gbit VM1 auf Host1 zu VM3 auf Host2: 1Gbit VM2 auf Host1 zu VM3 auf Host2: 10Gbit Die Geschwindigkeit teste ich mit NetIO 1.33, die Ergebnisse sind reproduzierbar. An den VMware Tools und somit den Treibern der VMXNET3 scheint es nicht zu liegen, denn auch VMs mit älteren Versionen von 2015 kriegen die volle Geschwindigkeit. Außerdem kriegen die betroffenen VMs ja zu welchen auf demselben Host die volle Geschwindigkeit. Auch das OS scheint keinen Einfluss zu haben. Ich finde auch in den Eigenschaften der vSwitches oder der VMs keinerlei Einstellungen, die zum Problem passen würden. Die Tests im anhängenden Beispiel (192.168.3.32 ist eine betroffene langsame VM) gingen von Host 2 -> Host 3 Host 2 -> Host 1 (langsam) Host 2 -> Host 1 (schnell) Hier noch ein Schaubild meiner Tests, worin zu sehen ist, dass einzelne VMs betroffen sind, nicht aber die Hosts untereinander. Alle VMs haben den VMXNET3 Adapter und zeigen 10Gbit an. Rot = 1Gbit Grün = 10Gbit