jesada
-
Gesamte Inhalte
15 -
Registriert seit
-
Letzter Besuch
Letzte Besucher des Profils

Fortschritt von jesada
")





-
Versteckte Datenbank umziehen Speicherort
jesada antwortete auf ein Thema von jesada in: MS SQL Server Forum
Versuch 1: Nach dem Herunterfahren der SQL Server Rolle (Instanz), habe ich den Ordner kurz umbenannt, mit dem Versuch, dass diese beim Start dann nicht benötigt werden oder im Stammverzeichnis angelegt werden. Leider ist dann die SQL Server Instanz nicht mehr hochgefahren. Somit war der Punkt dann nicht zielführend. Versuche 2: Ich habe die SQL Rollen auf allen Nodes entfernt. Danach habe ich die SQL Rolle wieder installiert mit dem neuen Ziel. Die Datenbank wieder eingespielt und die Nutzer wieder auf der Instanz angelegt. Hat reibungslos funktioniert. Wenn es keinen offiziellen Weg gibt diese zu machen, könnte das ein Ansatz sein. Nachteil, die Datenbank ist für diesen Prozess, bis der erste Node Online ist, nicht erreichbar. Danke für eure Hilfe Grüße -
Versteckte Datenbank umziehen Speicherort
jesada antwortete auf ein Thema von jesada in: MS SQL Server Forum
Ich werde die Datenbank Morgen mal versuchen umzuziehen. Versuch 1: Datenbank Offline nehmen und die Daten Verschieben (Sicherung). Danach die Datenbank wieder Online nehmen mit der Hoffnung dass er im Stammpfad diese neu anlegt, oder erst gar nicht benötigt. Versuch 2: Rolle auf beiden Nodes entfernen und mit den selben Daten, jedoch auf dem neuen CSV einrichten und wiederherstellen. Den Versuch mit den Laufwerksbuchstaben kann ich mir als Lösung nicht vorstellen. Da die Platte nur aktiv ist, wenn auch die Rolle auf einem Knoten aktiv ist. @Dukel hast du damit schon Erfahrung? Beste Grüße -
Versteckte Datenbank umziehen Speicherort
jesada antwortete auf ein Thema von jesada in: MS SQL Server Forum
Der Cluster bleibt wie er ist, zumindest die Knoten. Jedoch müssen die SQL Rollen auf einen neuen CSV ziehen. Ich kenne das von den Umgebungen ohne Cluster, dass man die Datenbank umziehen kann vom Speicherort. Das geht auch soweit, bis auf die vier benannten Datendateien. Diese bleiben aktiv und lassen sich auch nicht löschen, solange die Instanz Online ist. Somit kann ich die alten CSV´s nicht löschen, da die Instanz noch aktiv auf diese vier Datendateien zugreift. Wie sich sich die SQL Rolle verhält, wenn ich diese vier Datendateien im Offline Zustand entferne, teste ich noch. Halte dich gerne auf dem laufenden. Beste Grüße -
Versteckte Datenbank umziehen Speicherort
jesada antwortete auf ein Thema von jesada in: MS SQL Server Forum
Hallo Nils, das mit den Vorlagen habe ich so nicht herausgelesen, eher dass es das Konstrukt zum Failover oder HA Cluster ist. Das würde bei mir auch zutreffen. Da der Cluster von der Instanz auf ein anderes Share umziehen muss, müssten die Daten mit. Es gibt keine Option im Cluster oder in der Instanz den Umzug der Datendateien von diesen vier Dateien zu bewerkstelligen. Bisher habe ich nur gelesen, dass man die Instanz löschen muss und diese neu aufbauen muss, danach dann das Backup wieder einspielen. Lasse mich gerne eines besseren belehren Danke für eure Unterstützung. -
Versteckte Datenbank umziehen Speicherort
jesada antwortete auf ein Thema von jesada in: MS SQL Server Forum
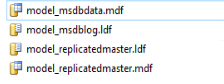
Das sind wohl Datenbanken die ab der 22er Version von MS mit eingerichtet werden, warum diese versteckt sind, versteh ich auch nicht. -
Hallo zusammen, ich würde gerne wissen, wie man Dateien von der Versteckten Datenbank umziehen kann. Die Befehle für die anderen Systemdatenbanken sind mir bekannt. Ziel ist es , diese Dateien von Laufwerk E auf Laufwerk F umzuziehen. Mit bestem Dank

-
Cluster mit 2 Nodes mit mehreren Instanzen
jesada antwortete auf ein Thema von jesada in: MS SQL Server Forum
Danke für die Antworten. Vom Systemdesign haben wir keinen Bedarf an so einem Konstrukt, es ging mir nur allgemein um die Möglichkeit der Umsetzung. Werde dann in der Umgebung wie MS das angibt ein CSV (DB,LOG,Backup) für eine Instanz einrichten. Besten Dank -
Cluster mit 2 Nodes mit mehreren Instanzen
jesada antwortete auf ein Thema von jesada in: MS SQL Server Forum
Hallo Nils, danke für deine Antwort. Wäre es denn Sinnvoll, je Funktion eine CSV anzulegen. Ergo eine CSV01 - Backup CSV02 - Log CSV03 - Database Und beide Nodes mit mehreren SQL Instanzen so arbeiten zu lassen? Also mehrere SQL Instanzen legen jeweils Ihre SQL Daten auf die CSVs. Macht sowas Sinn? -
Cluster mit 2 Nodes mit mehreren Instanzen
jesada antwortete auf ein Thema von jesada in: MS SQL Server Forum
Danke für deine Antwort, die Argumente dafür wie auch dagegen sind mir bekannt. Wir betreiben jedoch verschiedene Instanzen (Kritisch bis unkritisch) für mehrere Mandanten, diese betreibe ich ungern in einer Instanz. Das Memorymanagement ist dann halt immer händisch zu machen. -
Guten Morgen zusammen, wir würden einen SQL Cluster aufsetzen wollen mit zwei Knoten. Auf diesen Knoten würden wir dann die jeweiligen Instanzen für die Abteilungen betreiben wollen. Macht es hier Sinn die Rollen immer auf die gleichen Clustervolumes zu betreiben oder sollte jede instanz ein eigenes Volume erhalten? Beispiel: Instanz 01 auf CSV 1 DB, Backup,Log Instanz 02 auf CSV 1 DB, Backup,Log Oder die alternative: Instanz 01 auf CSV 1 DB, Backup,Log Instanz 02 auf CSV 2 DB, Backup,Log Danke und schönen Tag euch Grüße Jesada
-
vmfs 5 Migration auf vmfs 6 mit FS Expand
jesada antwortete auf ein Thema von jesada in: Windows Server Forum
Besten Dank für deine schnelle Antwort. Da bin ich wohl im Schreibfluss entgleist Selbstverständlich meine ich die VM. Besten Dank -
Hallo Zusammen, wir betreiben einen VCenter mit mehreren Hosts. Einer hiervon ist der FS mit 4 TB auf Windows 2016 (bisher noch ohne DFS). Das derzeitige System läuft auf vmfs 5. Ich würde im Zuge der Migration auf vmfs 6 wie folgt vorgehen: 1. Erstellung eines neuen LUN / LDEV mit 5 TB 2. Einbindung des neuen LDEV als vmfs 6 auf dem vCenter 3. Migration des FS auf den neuen DS 4. Expand Volume auf dem FS Spricht gegen dieses vorgehen was? Hat hier schon einer Erfahrungen sammeln können ? beste Grüße Dave
-
Sorry wenn ich mich da ein wenig doof formuliere. Das ich nach der Installation eines Windows OS den GRUB anpassen muss, ist mir klar und würde ich auch in kauf nehmen. Wäre es dann möglich über den WDS das System zu installieren? Ergo Modify Disk0P1 Typ=Start / Create und Modify Disk0P4 Typ=System ?
-
Wie meinst du das? Das ich den GRUB Nachbearbeiten muss ist mir klar. Da ich ja Windows in den GRUB mit aufnehmen muss.
-
Hallo an alle hier im Forum, Vielleicht hat ja schon jemand dieses Szenario gehabt. Auf unseren Testgeräten 40Stk (Normale Computer) ist derzeit auf zwei verschiedenen Partitionen Linux installiert. Mein Ziel ist es, nun auf den freien nicht zugeordneten Speicher der Festplatte ein Windows 7 zu installieren über den WDS (Windows 2008R2). Jede der beiden Linux Partitionen hat derzeit 250GB zugeordnet. 500GB sind noch nicht zugeordnet, wobei hiervon 250GB für mein Vorhaben genutzt werden sollen. Zusammenfassung: IST: Disk0P1 - EFI /GRUB 8GB Disk0P2 - Linux 250GB Disk0P3 - Linux 250GB nicht zugewiesen: ~500GB SOLL: Disk0P1 - EFI /GRUB 8GB Disk0P2 - Linux 250GB Disk0P3 - Linux 250GB Disk0P4 - Windows 7 250GB nicht zugewiesen: ~250GB Wie gebe ich das in der Unattend an damit er das so nimmt? Mit dem jetzigen Versuch sagt er mir das die Konfiguration nicht analysiert werden kann. Ist die OrderID dann eins oder ist Sie dann wie die PartID 4?