pitcare
-
Gesamte Inhalte
13 -
Registriert seit
-
Letzter Besuch
Fortschritt von pitcare
")





-
Servus, ich baue gerade eine Testumgebung auf, Basis ist - Windows Server 2016 - GatewayServer - 2 x Webaccess - derzeit 2 Sessionhosts Ziel wird es sein Zugriff sowohl intern also auch extern auf die Sessionhosts zu erhalten. Das klappt soweit auch ganz gut. Natürlich möchte ich SSO verwenden, damit der Benutzer sich lediglich einmal im Webinterface anmeldet und von dort auf seine freigegebene Ressource anmelden kann. Auch das hat einwanfrei funktioniert mit dem ersten User. Die ensprechenden GPO zum durchreichen der Anmeldeinformationen, das hinterlegen des Hashcodes für das verwendete Zertifikat, alles tuti. Aber wenn ich nun der Sammlung einen weiteren User hinzufüge, kann ich mich zwar im Webinterface mit dem Benutzer anmelden, aber öffnet die Session des ersten Users. Klingt seltsam oder? Also User 1 > ist in Sammlung 1 User 2 > ist in Sammlung 1 User 1 >loggt sich mit seinen Daten im Webinterface an > verbindet sich zu Sessionhost als User 1 User 2 >loggt sich mit seinen Daten im Webinterface an > verbindet sich zu Sessionhost als User 1 Das heißt, er scheint beim SSO die Benutzerdaten von User 1 immer weiterzugeben? Kennt jemand das Problem? Wäre für einen Tipp dankbar, falls mehr Informationen gebraucht werden, dann nur zu... Vielen Dank im vorraus Grüße Stefan
-
Dokumentation eines Netzwerks
pitcare antwortete auf ein Thema von Dutch_OnE in: Windows Server Forum
Hi, wir haben uns glpi und OSCinventory zugelegt. Die Glpi Software ist soweit schon komplett fertig, allerdings dauert es ein bisschen bis man sich richtig reingefuchst hat. Wir haben alle Switchs, Ports bis zum Client in diesem System erfasst. Die Software ist opensource und for free, in Verbindung mit OSCinventory funktioniert auch die über GPO angeschobene Inventarisierung einwandfrei. Kann ich nur empfehlen. -
Backup Wiederherstellung Windows Server 2012 R2
pitcare antwortete auf ein Thema von pitcare in: Windows Server Forum
Hi Tobias, jawoll das war die Lösung. Grüße Stefan -
Backup Wiederherstellung Windows Server 2012 R2
pitcare hat einem Thema erstellt in: Windows Server Forum
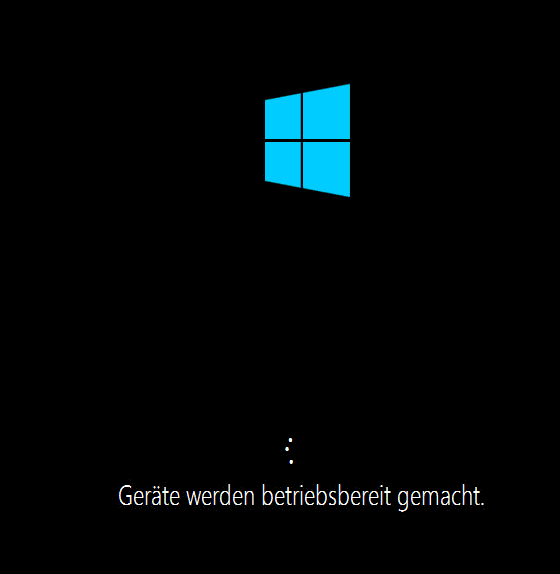
Hallo zusammen, folgendes Szenario bereitet mir erheblich Kopfschmerzen: Symantec Backup 2014 SP1 > Wiederherstellung eines Windows Server 2012 R2 auf unserer VMware Farm ESX 5.1 Die Sicherung des Servers ist ohne Fehler gelaufen, die Wiederherstellung aus Symantec auch. Beim starten des Servers bleibt die Kiste hängen mit folgender Meldung: "Geräte werden betriebsbereit gemacht". Aus der Vergangenheit und ähnlich aufgetretenen Problemen hatte ich anfangs vermutet das er die Startpartion eventuell nicht findet, und versucht eine Systemreparatur auszuführen und den Bootloader zu reparieren. Leider ohne Erfolg. Beim Starten des System mit einer PE Version habe ich in der Datenträgerverwaltung gesehen das er der Systempartion das Laufwerk c: gegeben hat, und dem eigentlichen System mit den Daten Laufwerk e: In beiden Partionen steht : Fehlerfrei, Primäre Partition. Den Flag "System" habe ich nicht gesehen. Vielleicht liegt hier der Hase im Pfeffer. Kennt jemand diesen Fehler? Wäre für einen guten Tipp dankbar. Grüße Stefan
-
Exchange 2013 Migration und FolgeFehler
pitcare antwortete auf ein Thema von pitcare in: MS Exchange Forum
Hi Robert, bezüglich Outlook, hier hatte ich die Regeln händisch aus Outlook bzw. aus OWA gelöscht, gerade aber auch nochmal per cmd, allerdings erbringt eine Neuerstellung einer Regel keinerlei Änderung. Ich erhalte auch keinerlei Fehlermeldung. Bei uns sind übrigens alle Postfächer vom alten Exchange migriert. Die Nichtfunktion der Regeln betrifft auch nur einige Postfächer. Im Eventlog sind keine Fehler zu sehen, lediglich die Info nach dem Start des Programms das die u.a Postfachregeln angewandt werden. Seltsame Geschichte. Die Regeln an sich müssten aber auch laufen wenn ich ohne Outlook arbeite, also direkt im Webinterface funktionieren, auch dort hat das löschen und Wiederhinzufügen einer Regel keine Änderung gebracht. bezüglich Symantec: Hier habe ich die aktuelleste Version von Backup Exex 2014 Version 14.1.1786 im Einsatz, (SP1 und einem aktuellen Hotfix, bei dem es auch um einen ähnlichen Bug ging. http://www.symantec.com/business/support/index?page=content&id=TECH225092 Ich werde als nächstes das CU 6 nachziehen. Vielen Dank erstmal für Deine Beitrag. Stefan -
Exchange 2013 Migration und FolgeFehler
pitcare antwortete auf ein Thema von pitcare in: MS Exchange Forum
In der Regel fällt es mir schwer Fehlermeldungen in Servern zu ignorieren, und nur darauf zu reagieren wenn irgendwo nichts mehr geht. Deswegen hatte ich u.a. auch die beiden Exchange Meldungen oben mit in den Post aufgenommen, um zu sehen, ob jemand hier im Forum gleichlautende Meldungen hat. Meistens ist man damit eben nicht alleine. Von einem gut geschrieben Blog hatte ich die Empfehlung 12 GB, 4 CPU für unsere Größenordnung übernommen. Ich werde den Speicher erhöhen, ein Versuch ist es wert. Problem 1: Die angelegten Postfachregeln funktionieren nicht automatisch nach der Migration, sondern nur wenn man das Regelwerk händisch ausführt. Da habe ich mich vielleicht nicht ganz klar ausgedrückt. Das ist nicht bei allen Postfächern, sondern nur einige wahllos. Problem 2: Das der BackupJob c2t nichts mehr mit dem Exchange zu tun hat glaube ich allerdings nicht mehr, hierfür gibts bei ähnlichen Fällen einige Knowlege Bases bei Symantec die etwas anderes aussagen. Das Problem ist hier, das GRT beim Tape Copy Job nicht richtig funktioniert, (einer der beliebten VFF Writer Fehler) beim B2D funktioniert das noch. Die unten stehende Fehlermeldung nur zur Info. -
Exchange 2013 Migration und FolgeFehler
pitcare antwortete auf ein Thema von pitcare in: MS Exchange Forum
Hi Robert, Es gibt ca. 100 Postfächer auf dem Server. Die Meldung mit dem Speicher führt wahrscheinlich dazu, das die Sicherung vom Backup nicht ganz ohne Fehler verläuft, B2D funktioniert noch einwandfrei, nachfolgende Sicherung auf Tape soll lt. Symantec Knowlegebase mit fehlenden Ressourcen zusammenhängen. Für 32 bit Systeme gab es hier noch eine Lösung, da hier die gleiche Fehlermeldung den selben Fehler produzierte wie ich ihn jetzt habe. (http://support.microsoft.com/KB/304101) Ansonsten ist es natürlich ärgerlich wenn Postfachregeln nicht mehr funktionieren, das kann ich nicht weg ignorieren. -
Hallo zusammen, nach der Migration von Exchange 2010 auf 2013 gibt es jetzt noch einige kleinere Fehler zu beheben. Meine Konfig: Windows Server 2012 R2 Exchange Server 2013 Build 847.32 Clients Outlook 2013 Ereignislogs: Der Leistungsindikator '\\EXCHANGE2013\LogicalDisk(C:)\Free Megabytes' hatte während des 15-minütigen Intervalls mit Start bei '05.12.2014 08:11:00' einen Wert von '7.320,00'. Weitere Informationen: None. Triggername:DatabaseDriveSpaceTrigger. Instanz:c: Der Leistungsindikator '\\EXCHANGE2013\LogicalDisk(HarddiskVolume1)\Free Megabytes' hatte während des 15-minütigen Intervalls mit Start bei '05.12.2014 08:11:00' einen Wert von '59,00'. Weitere Informationen: None. Triggername:DatabaseDriveSpaceTrigger. Instanz:harddiskvolume1 Die Meldung schien ein Bug zu sein bis zum CU 3. Taucht bei aber immer noch als Fehler im Eventlog auf und das leider ständig. Speicher: Der Exchange hat 12 GB Arbeitsspeicher und 4 CPU. Anfangs habe ich ihn mit 8 GB laufen lassen, eine Erhöhung des Arbeitsspeichers hat an der unten stehenden Meldung nichts geändert. Er nimmt sich alles was er kriegt :-) Information Store - DB01 (6976) Ein erheblicher Teil des Datenbankcaches wurde in die Auslagerungsdatei des Systems geschrieben. Dies kann zu einer erheblichen Leistungsverringerung führen. Ausführliche Informationen zu den möglichen Ursachen finden Sie über den Hilfelink. Vorheriger Zustand vorhandener Cache: 85% (22725 von 26733 Puffern) (vor 1140 Sekunden). Aktueller Zustand vorhandener Cache: 79% (21374 von 26733 Puffern). Aktuelle Cachegröße gegenüber Ziel: 99 % (764.496 / 767.938 MB) Physischer Arbeitsspeicher/RAM-Größe: 12287.488 MB Postfachregeln: Ich habe nach der Migration bei den betreffenden Usern die Regeln komplett gelöscht und wieder neu angelegt. Das manuelle Ausführen der Regeln funktioniert einwandfrei. Clientseitig schliesse ich den Fehler aus, da auch im OWA der Fehler auftritt, wenn ich dort die Regeln neu anlege. Mir scheint also so, als wäre die Ursache direkt beim Exchange zu suchen. Vielleicht gibts ja jemanden der noch ähnliche Probleme hat. Würde mich über einen Austausch freuen. CU6 werde ich noch nachziehen, das wird aber an den bestehenden Problemen so weit ich das erlesen konnte nichts helfen. Grüße Stefan
-
Deutsche Bezeichnungen Powershell deleted items
pitcare antwortete auf ein Thema von pitcare in: MS Exchange Forum
Hi Norbert, für die Nutzung der Aufbewahrungsrichtlinie sind Enterprise Cals notwendig oder? Die haben wir aber leider nicht. Gruß -
Deutsche Bezeichnungen Powershell deleted items
pitcare antwortete auf ein Thema von pitcare in: MS Exchange Forum
Hallo und vielen Dank für Eure Antworten. Bei uns im Hause werden u.a. größere Datenmengen per Mail verschickt, und auch empfangen. Das führt dazu, das ich immer wieder gebeten werde, wenn die entsprechenden Kollegen mal nicht aufgeräumt haben, oder sich in den Urlaub verabschiedet haben, das Postfach voll läuft. Es macht keinen Sinn, die Postfachgröße zu erweitern, auch wenn das rechtlich die einzig korrekte Lösung wäre. Deshalb werde ich von der Leitung gebeten alte Nachrichten zu löschen, das funktioniert mit dem oben genannte Befehlt ganz prima, dadurch werden alle "emfangen" Nachrichten älter als gelöscht. Mir wäre es aber lieber, einfach nur die schon gelöschten Nachrichten und noch im Papierkorb vorhanden komplett zu löschen. Wäre der Exchange Server auf Englisch installiert, könnte man die Deleted items einsetzen. ja, aber nur nach Bedarf. Grüße -
Deutsche Bezeichnungen Powershell deleted items
pitcare hat einem Thema erstellt in: MS Exchange Forum
Hallo zusammen, kann mir vielleicht jemand sagen wie die deutschen Bezeichnungen für deleted items ist. Beispiel: Löschen von Nachrichten per Powershell earch-Mailbox -Identity "user" -SearchQuery "empfangen:<05.05.2012" -DeleteContent der Posteingangsordner wird beim löschen deutsch angegeben wie im Beispiel oben. Ich kann leider nirgends die gültigen Bezeichnungen für deleted items finden und Nachrichten via Powershell zu löschen. Vielleicht kann von Euch jemand helfen. Danke und Gruß Pitcare -
Hallo und vielen Dank für Eure Antworten. Ich konnte mittlerweile das Problem indentifizieren mit Hilfe von Wireshark. Ich habe gesehen das unglaublich viele Broadcasts im Netzwerk unterwegs waren, von einem Offline geschalteten NFS Volumen, das in einer ESX Farm hing. Die 5 ESX Server haben unentwegt versucht auf den Datastore zuzugreifen, damit sind die 2824er wohl überhaupt nicht klar gekommen. Danke nochmal.
-
Hallo zusammen, ein guter Tip ist an Tagen wie heute vielleicht Gold wert, wer möchte schon gerne Probleme über die Ostertage offen lassen. In unserem Netzwerk haben wir mehrere HP Pro Curve Switches, mit verschieden VLANS. Das Netzwerk an sich funktioniert reibungslos, allerdings funktioniert seit gestern bei dreien der vorhanden 5 Switche der Zugriff aufs Management per SSH nicht mehr. Ein Ping verrät mir, das es sehr lange dauert bis die Switche antworten, bei manchen versuchen kommt auch gar keine Antwort zurück. Es wurden in der Konfig in den letzten Wochen keine Veränderungen vorgenommen, außer eventuell das taggen von Ports. Da der reine Datenverkehr reibungslos untereinander funktioniert und auch keinerlei Fehler auf den Switchen angezeigt werden bin ich etwas ratlos. 3x HP Pro 2824 1x HP 5308 XL 1 x HP 4108GL Die beide großen sprechen miteinander ohne Problem und sind auch vom Netz erreichbar. Wenn ich mich direkt auf einen Port der 2824 einklinke, können die beiden großen angesprochen werden, die beiden anderen 2824 sind ebenfalls nur sporadisch an pingbar. Ein Reboot habe ich auf allen Switchen bis auf den 5308 durchgeführt. Da keine Fehler auf den Switches und auch der sonstige Datenverkehr läuft schliesse ich auch fehlerhafte Kabel etc....aus. Kennt wer vielleicht dieses Phänomen? Grüße der Stefan