Maraun
-
Gesamte Inhalte
609 -
Registriert seit
-
Letzter Besuch
Alle erstellten Inhalte von Maraun
-
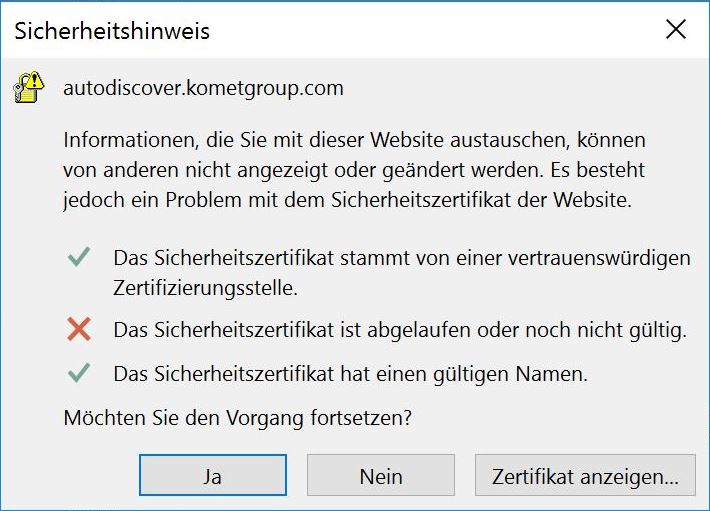
Exchange 2010 / Outlook 2010 Autodiscover Sicherheitzszertifikat
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Also das Zertifikat habe ich auf dem Exchange bereits vor Wochen erneuert, weil es abgelaufen ist nach 5 Jahre....webmail.domain.com. Services dafür sind IMAP, POP, SMTP und IIS. Auf den Exchange-Servern ist das Zertifikat auch aktuell gültig bis 2022, also erneut 5 Jahre. Aber auf den Clients ist das Zertifikat bisher nicht verteilt. Seltsamerweise meckern nur zwei Rechner. Bei mir im eigenen Zertifikateordner des benutzers ist es auch vorhanden und abgelaufen (10.04.2017). Wie verteile ich das jetzt neu? -
Exchange 2010 / Outlook 2010 Autodiscover Sicherheitzszertifikat
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Okay, mache ich. Aus dem Gedächtnis heraus kann ich sagen, dass das Zertifikat abgelaufen ist. Ob das Datum am Surface stimmt, werde ich prüfen. -
Exchange 2010 / Outlook 2010 Autodiscover Sicherheitzszertifikat
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Wo genau muss ich dieses Zertifikat finden? autodiscover.domäne.com Ich finde das in keinem Zertifikatsspeicher oder unter IE, Inhalte, Zertifkate. -
Exchange 2010 / Outlook 2010 Autodiscover Sicherheitzszertifikat
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Hi; wir nutzen 2x Transport, 2x Postfachserver ohne Load Balancer. Muss mich korrigieren. Wir nutzen seid kurzem Surfaces (knapp 30 Stück verteilt) und die haben Windows 10 mit Outlook 2013. Und auf eben einem diesen Surfaces erscheint der Fehler. Allerdings ist es das einzige Surface mit diesem Problem. Exchange 2010 ist auf dem aktuellesten Stand. Der User wurde bisher nicht an einem anderen Rechner getestet. Proxy muss ich ebenfalls prüfen.
-
Exchange 2010 / Outlook 2010 Autodiscover Sicherheitzszertifikat
Maraun hat einem Thema erstellt in: MS Exchange Forum
Hallo zusammen, wir nutzen eine exchange 2010-Serverfarm mit Outlook 2010 und circa 1500 Clients. Jetzt meldet ein Rechner bei jedem Outlook-Start, dass die Autodiscover.xml abgelaufen oder nicht mehr gültig ist. Das Zertifikat hat ein altes Datum. Ich habe bereits versucht, das Zertifikat erneut zu installieren (Zertifikat anzeigen, installieren in vertrauenswürdige Stammzertifizierungsstellen. Das hat einmalig nach dem Outlook-Start geklappt. Aber einen Tag danach bringt der Client denselben Fehler wieder. Wie kann ich diesen Fehler an dem einen Client beheben? Viele Grüße -
Outlook 2010 - Ordner XYZ als Typ Kontakt per Powershell
Maraun hat einem Thema erstellt in: MS Exchange Forum
Hallo zusammen, für ein CRM-System müsste ich bei circa 150 Benutzer in Outlook einen zusätzlichen Ordner vom Typ Kontakt erstellen. Wir nutzen Exchange 2010 mit Outlook 2010. Aufgrund der Sprachthematik sollte der Ordner auch direkt unterhalb des Postfaches stehen. In Outlook geht das manuell (Postfach markieren, Neuer Ordner, Typ Kontakt). Nach dem Erstellen ist der Ordner über die Ordnerliste sichtbar. Hat das schon mal jemand per Powershell gescripted/realisiert? Da ich jetzt nicht manuell alle 150 Ordner im jeweiligen Outlook mit den Zugangsdaten anlegen möchte. Danke und Gruß -
Hallo zusammen, wir nutzen neu installierte Surfaces mit Win10 1607 Professional in der Domäne und würden gerne die Gesichtserkennung nutzen, ohne den Fallback-Pin. Soweit ich das jetzt nachlsese, geht das aber nicht. Ich habe per GPO folgendes geändert: Computer Config, Policies, Admin templates, System, Logon, Turn on convenience Pin sign-in DISABLED Dadurch bleiben die bisher ausgerollten Surfaces unberührt und können sich weiter per Face/PIN einloggen. Nehme ich jetzt aber manuell den PIN raus, dann geht gar keine ANmeldung per Windows Hello (Gesichtserkennung) mehr. Gibt es eine Lösung, um die Gesichtserkennung ohne Pin zu nutzen?
-
Fileserver 2012 - Alias für Freigabe
Maraun antwortete auf ein Thema von Maraun in: Windows Server Forum
@daabm: Das Problem ist ja, dass quasi eine Freigabe unter einem anderen Namen zusätzlich aufgerufen werden soll und dieser Name auf einer anderen Ordnerebene liegt. So müsste die zusätzliche Freigabe eben per \\ definiert werden. Und genau das ist das Problem. Aufgabe: Daten umziehen und Alias setzen für \\server\freigabe1 auf \\server\freigabexyz\freigabe1. Es geht nicht darum, irgendeinen Freigabenamen zu geben, sondern einen, aus der ersten Ordnerebene (quasi so wie es vor dem Umzug war). -
Hallo zusammen, aufgrund einer Abteilungszusammenlegung und bestehender Links auf zahlreiche Dateien/Ordner, wollte ich mit Freigabe-Aliase arbeiten. Im 2012er Fileserver kann ich ja zusätzliche Freigaben zu einer bereits bestehenden Freigabe hinzufügen. Beispiel: \\Server\Freigabe1 -> zusätzlich aufrufbar mit Freigabe \\Server\Freigabexyz. Auf der ersten Ebene funktioniert das wunderbar. Ich kann den Ordner umbenennen und den Alias setzen. Aber jetzt geht es darum, einen Abteilungsordner aus der ersten Ebene in die zweite Ebene (Unterebene) zu verschieben. Und dabei funktioniert der neue Alias aufgrund von Sonderzeichen (\\) nicht mehr. Beispiel: \\Server\Freigabe1 -> Soll umgezogen werden nach \\Server\Freigabexyz\Freigabe1 und als \\Server\freigabe1 weiterhin aufrufbar sein aufgrund der Links. Mit DFS geht das natürlich und wenn es keinen anderen Weg gibt, nutze ich den auch. Meine Frage ist nur, ob es einen anderen Weg per Alias gibt, oder nicht. Danke vorab.
-
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Ja, aber wie Du ja schon schreibst, damals mit iOS 6.1. Und unser Problem besteht bereits seit 19./20.04. Denke, es wäre mittlerweile publik, wenn es wirklich ein Problem mit iOS geben würde. Wenn man nur die Tlogs vernünftig analysieren könnte, denn da sollte ja eventuell das Problem sichbar sein. -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Also ich habe vorher nochmals die Active Sync Datenstatistik mit anderen Tagen/Wochen verglichen. Ebenso die momentanen Mailboxgrößen auf den zwei Datenbanken. Bei beidem ist nichts auffälliges oder etwas, das direkt ins Auge sticht. Somit wird wohl das vorgehen mit dem Umzug in eine neue DB die einzige Vorgehensweise sein. -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Das kann ich auch verstehen, aber gestern hatte ich zwei Airwatch-Techniker dran und ich habe mehrfach Mails von einem iPhone an mein Outlook und zurück gesendet. Wie bereits erwähnt, fanden wir nur ganz normale einzelne IIS-Einträge für den Sendevorgang. Damit ist von Seiten Airwatch bewiesen, dass das Problem auf dem Exchange sitzt. Es ist so, als ob er für jedes normale gesendete/empfangene Mail von einem Mailbox-User dieser beiden DBs das zigfache an Tlogs geschrieben wird. -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Hi Jan, ja habe ich. Als die aber vernahmen, dass 3rd Party Anwendungen (Mailarchiv, MDm) involviert sind und die Tlogs sich nach dem stoppen der Airwatch SEG-Dienste wieder beruhigen, war es das für die. Zumal darauf verwiesen wurde, dass für eine tiefere Analyse ein Premiervertrag notwendig ist. Es würde schon mal helfen, wenn man irgendwie die Tlogs mal analysieren könnte. Eben nochmals für beide DBs die Postfachgrößen gecheckt, aber es ist einfach kein Ausreisser oder Verursacher erkennbar. Die Replication Block Mode Meldung ist ja nur eine Folge der vielen Tlogs, die geschrieben werden. Gruß Alex -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Also mittlerweile sind jeweils Support-Mitarbeiter der Mailarchivierung und der MDM Lösung auf unseren Systemen gewesen, ohne den fehler zu finden. Bzw. ist laut denen klar, dass es nicht ihre Software verursachen kann. Das Airwatch-SEG schreibt pro Mail ein IIS-Log auf dem SEG und auf dem Exchange. Nichts wird vervielfältigt oder multipliziert. Die Zahlen mit knapp 4000 Tlogs pro Stunde, die jeweils nur für die beiden großen DBs geschrieben werden, sind nach wie vor der Fall. Habe nur noch die Idee, die zwei DBs neu anzulegen. Hat von Euch noch jemand einen Ansatz auf dem Exchange? Die einzige Umstellung bisher war der Wechsel von netBackup auf Veeam als Backup. Das Eventlog zeigt mir dauern folgendes: Continuous replication block mode is unable to keep up with the data generation rate. Block mode has been suspended, and file mode has been resumed. Kommt für beide DBs im Eventlog auf dem Mailboxserver. Viele Grüße Alex -
Hi, Exchange 2010 SP3 RU17, 2x Transport, 2x Postfachserver. Set-TransportConfig-MaxRecipientEnvelopeLimit 100 gesetzt. Gilt das nur für interne Adressen? Oder kann ich das Limit anders setzen, dass z. B. die Mitglieder in der Verteilerliste einzeln zählen? Ein User hat einen Newsletter mit zahlreichen Verteilerlisten und insgesamt mehr als 700 Empfänger, die aber größtenteils extern sind. Und er kann die Mail problemlos senden. Get-TransportServer | fl Name, PickupDirectoryMaxRecipientsPerMessage Name : Transport-1 PickupDirectoryMaxRecipientsPerMessage : 100 Name : Transport-2 PickupDirectoryMaxRecipientsPerMessage : 100 Danke und Gruß
-
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Hi, wobei ich erwähnen muss, dass die Journal Mailbox NICHT in einer der beiden DBs liegt, deren Tlogs so rapide ansteigen/geschrieben werden. -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Hallo zusammen, muss meinen Thread hier nochmals beleben, da irgendwie keiner einen Fehler bei uns findet: Exchange und Mailarchiv-Consultant war 2 Stunden remote auf dem System, ohne sichtbaren Erfolg. Airwatch Support hat einen Querschnitt/Ausschnitt der Tlogs analysiert und meint, dass das ganz normale Mails udn ActiveSync-Anfragen sind. Zahlen zu unserem Problem: 2 Datenbanken von 5 Stück in unserer DAG schreiben laufend Tlogs. Alle DBs, die DB-Copys und der ContentIndexState sind mounted und healty. DB1 Partitionsgröße: 1.29TB DB-Größe: 1.04TB Postfächer: 652 Logfiles in der Stunde: 3796 DB2 Partitionsgröße: 1.56TB DB-Größe: 1.42TB Postfächer: 761 Logfiles in der Stunde: 4334 Dazu haben wir circa 500 mobile Devices. Das heißt, am Tag werden pro DB etwa 35-40GB an Tlogs geschrieben, die Nachts von Veeam abgeräumt werden. Aber warum? Traffic durch bestimmte User oder ios etc. bereits getestet. Mailarchivierung läuft parallel und räumt Mails aus dem Journal ab. Aber die Journal-Mailbox ist mit 1,5GB abgeräumt und up-to-date. Die Journal-Mailbox liegt in einer seperaten DB, deren Tlogs auch nicht über Standard anwachsen. Hat jemand noch eine Idee, bezüglich des TLogs-Wachstums? Danke und Gruß -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Eine ganz vage Theorie, die vielleicht jemand mit Erfahrungswerten speziell Richtung ActiveSync von MDM Devices ad absurdum oder eventuell bestätigen kann. Mitte Februar habe ich ActiveSync über unser TMG per Firewall Policy abgestellt. Seitdem kommen nur noch MDM-Geräte Per Airwatch-Mailgateway durch die DMZ auf die Mailserver mit ActiveSync. Seit diesem Datum funktioniert unsere Mailarchivierung nicht mehr. 3rd Party Tool von metalogix, mit Journal und Postfacharchivierung. Vor einer Woche etwa haben wir unser Backup auf Veeam umgestellt. Jetzt die Theorie: Seit der Abschaltung des MS TMGs haben wir diese Auslastung und den Plattenanwuchs auf den Postfachservern. Bisher ist es nicht aufgefallen, weil es keine Events gibt und Nachts das Backup die TLogs weggeräumt hat. Nach der Umstellung auf Veeam lief das Backup nicht sauber und die Platten liefen voll. Durch die Auslastung konnte die Mailarchiv-Software die Postfächer nicht mehr richtig erreichen bzw. Archivieren. Zu der Theorie passt, dass ich Activesync-Daten verglichen habe und keinerlei Auffälligkeiten von Tagen sehe, bei denen alles noch in Ordnung war. Diese Theorie fußt aber darauf, dass solch eine Auslastung entweder normal ist bei 500 Devices, oder dass etwas nach wie vor 1200 Tlogs in 10 Minuten provoziert. Wir nutzen knapp 500 MDM-Devices. -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Hallo, ja, handelt sich definitiv um das Mailgateway. Sobald dort die Airwatch-Dienste und der WWW-Dienst down sind, ist alles wieder normal. Heute Morgen haben wir per Firewall alle internen/externen Connections unterbunden um zu sehen, ob das vom System oder den Devices kommt. Nachdem keine Connection mehr zustande kam durch die Devices hat sich alles beruhigt von den Tlogs. Habe jetzt mal Syncstatistiken zwischen dem 19.04. (noch keine Probleme) und den letzten Tagen erstellt (Activesyncreport.ps1). Ich sehe keine Auffälligkeiten wie mehr Hits, mehr Syncs oder irgendwas. -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Habs rausgefunden, Airwatch-SEG (MDM-Activesync). Sobald auf der Maschine in der DMZ die Dienste gestoppt werden, schreibt der Exchange circa 90-100 Tlogs in 10 Minuten. Sobald ich die Dienste wieder anstarte und Active-Sync auf den iPhone/iPad-Devices (knapp 500 Devices) funktioniert, wird das 10fache an Logs geschrieben für beide Benutzer-DBs. -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Der Performance Troubleshooting Assistent meldet dauernd Themen mit RPC/Mapi. Momentan hängen alle DBs (5 Stück) auf einem Postfachserver, bezüglich Veeam Sicherung. Hier die Meldungen vom Troubleshooting Assistent: The user ? caused 317889 log record bytes/sec to be written, which is greater than the threshold of 87381 MB/sec. MAPI client versions: 3587.33120.0. User's IP Addresses: hub/cas transportserver. MAPI process names: edgetransport.exe. -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Da arbeite ich mich gerade durch. Das Wachstum beträgt mittlerweile je 1GB an Tlogs pro Stunde für 2 große Datenbanken (1,04 und 1,4 TB). Alle anderen DBs bzw. Partitionen (3 weitere) auf denen Systemuser liegen, bleiben vom Wachstum ausgeschlossen. Habe mittlerweile erfolglos folgendes versucht: - Mailbox Database Kopien suspended und gelöscht - Alle Server mit RU16/17 und Windows Updates betankt - Alle Server heruntergefahren, so dass alle DBs auch mal komplett unmounted waren - 3d party Mailarchivierung deaktiviert - Officescan Virenscanner deaktiviert - Im Applicationlog wurde mir gemeldet, dass das Content Indexing für eine der zwei großen Dbs kaputt ist (Event 9877) -> Index neu erstellt, DB befindet sich gerade im Crawling. Das da Tlogs anwachsen verstehe ich. Aber auf der anderen großen DB eben auch. -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Was ist den bei Exmon normal an Werten? Hatte gestern einen User mit 100% CPU Auslastung auf dem Exchange. Alle mobilen Devices und Postfach Gerade gecheckt..vereinzelt ist da ein User mit 30%, aber auch nur vereinzelt und sporadisch. Die Platte läuft mit Tlogs weiter voll, selbst nach einer erfolgreichen Sicherung: 1GB in 10-15 Minuten. Sagt das jemandem was? Log record bytes/sec beyond error threshold The user ? caused 203515 log record bytes/sec to be written, which is greater than the threshold of 87381 MB/sec. Mapi client versions: 3587.33087.2 Users IP Addresses: IPs unserer Transportserver mapi process name: edgetransport.exe Habe jetzt beide Transport-Server und beide Postfachserver mit RU16/RU17 betankt und dadurch je 2x neu gestartet. Anhand der obigen Meldungen sieht es für mich nach Transportserver-Problem aus, wie es auch der Remote Troubleshooting Analyzer gemeldet hat. Jetzt ist das Wachstum sehr viel moderater und ausgebremster. Etwa 1GB alle 30Minuten. -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Also es sind circa 1500 User. IOS ist mindestens 7 und höher auf unseren Apple devices. Auf den Eventlogs kommt zur Zeit die Meldung das er in der Replikation umschaltet. Ansonsten wachsen eben die Tlogs für eine DB rasch an. Continuous replication block mode is unable to keep up with the data generation rate. Block mode has been suspended, and file mode has been resumed. Database: 3853542b-f326-45dd-ac20-8012898a6aa9 IoDepth: 3145680 IoLatencyInMsec: 202 Und die meldung erhalte ich auf dem Postfachserver auch in unregelmäßigen Abständen: Mapi session "483d7d0d-5036-457a-a1e6-8b72f300a20c: /o=XXXXX" exceeded the maximum of 600 objects of type "objtFolder". -
Exchange 2010 - DB läuft voll und Logs werden nicht abgeräumt
Maraun antwortete auf ein Thema von Maraun in: MS Exchange Forum
Jo, sorry, mein Fehler. Die Frage muss heißen, warum ich so viele Tlogs habe, bzw. diese nach wie vor minütlich erzeugt werden und ob ich da irgendwo ansetzen kann. Mit perfmon und Exmon bereits Auswertungen gefahren, ebenso mit Mailboxstatistics die Größen ausgelesen. Wir versuchen, mit Veeam zu sichern, aber irgendwie meldet er ständig, dass der VSSWriter nicht stable ist und räumt die Logs nicht ab. Aber kommt der Tlog-Zuwachs davon, dass wir seit 19.04. keine Logs mehr per Backup weggeräumt haben?