

RalphT
-
Gesamte Inhalte
658 -
Registriert seit
-
Letzter Besuch
Beiträge erstellt von RalphT
-
-
Danke dir. Ich habe einen Lancom, der ist derzeit nicht so wichtig. Da werde ich die 10.20 RU aufspielen. Dann mal sehen.
Auf der Lancomschulung hat man mir zig mal eingetrichtert, dass ich immer die neueste Firmware nehmen soll. Ok, ich gucke da nicht immer regelmäßig drauf. Vielleicht auch deshalb, weil alles funktioniert.
Bei der Sonicwall hatte ich auch mal ohne vorher nachzufragen, die neueste Firmware aufgespielt. Naja, danach hatte ich große Augen: Es waren im Firewallregelwerk nicht mehr alle Regeln zu sehen. Aber sie wirkten noch - zum Glück. Eine Nachfrage beim Händler ergab, dass es dort einen BUG gab. Regeln, die in der Beschreibung Umlaute hatten, wurden nicht mehr angezeigt.
Da gab es auch von der Sonicwall einen Beitrag dazu, wie man das wieder in Ordnung bringt.
-
Hmmm, also auf dem Problemlancom ist die 10.12.038RU9.
Auf einem anderen Lancom, der auch mal Probleme macht ist sogar noch die 9.24.0070 drauf.
Ich habe gerade nachgesehen: Derzeit ist 10.20 RU2 aktuell. Dazu muss ich sagen, dass ich bei keinen der Lancoms VRRP nutze. Dann könnte ich die doch nehmen - oder??
-
Moin,
ich habe hier schon länger ein Problem. Der VPN-Tunnel zwischen einer Sonicwall NSA 2600 und einem Lancom 1783 VAW ist nach einer gewissen Zeit immer gestört. Wenn das der Fall ist, dann ist zwischen den verbundenen LANs keine Datenübertragung mehr möglich. Zwischen der Sonicwall bestehen auch noch andere VPN-Verbindungen zu anderen Lancoms. Auch zwischen diesen Verbindungen tritt ab und zu mal dieses Problem auf. Auf der Sonicwall und auf dem Lancom ist der Tunnel immer noch verbunden.
Hier etwas zur Konfiguration:
Zwischen der Sonicwall und dem Lancom bestehen mehrere Netzbeziehungen. Auf der Sonicwallseite sind es derzeit 5 verschiedene LANs und auf der Lancomseite sind es 2 verschiedene LANs.
Der Fehler äußert sie wie folgt:Es wird oder wird nur meist nur eine LAN-Verbindung unterbrochen. Also die anderen bestehenden Netzbeziehung zwischen den beiden Firewalls funktionieren einwandfrei.
Jetzt ist natürlich die Frage, was ist an dieser gestörten LAN-Verbindung anderes? Da habe ich länger geforscht und bin jetzt der Meinung, dass das am Traffik liegt. Denn zwischen diesen LANs wird fließt der meiste Datenverkehr.Abhilfe schafft entweder ein erneuter, kompletter Tunnelaufbau auf der Seite vom Lancom oder ein erneuter Aufbau nur von diesem Netz auf der Sonicwall. (Button Renegotiate) Anschließend wird nur diese Netzbeziehung wieder erneut aufgebaut und das Problem ist für mehrere Stunden ok.
Auf der Lancomseite und Sonicwall habe ich folgende Werte für den Tunnel konfiguriert:
--------------- Sonicwall --------------
Phase 1:
Main-Mode
DH-Group 2
AES-128
SHA-1
Lifetime 108.000s
Phase 2:ESP
AES-128
SHA-1
Lifetime: 28.800s
--------------- Lancom --------------Phase 1:
AES-128
SHA-1
Liftetime: 108.000s
Phase 2:AES 128
SHA-1
Liftime: 28.800
0 kBytesHier die Netzbeziehungen (die habe ich zig mal auf beiden Seiten auf Richtigkeit kontrolliert):
Seite Sonicwall:
192.168.1.0/24
192.168.2.0/24
192.168.3.0/24
192.168.4.0/24
192.168.5.0/24Seite Lancom:
192.168.10.0/24
192.168.12.0/24
Hier wird auf beiden Seiten mit fester IP-Adresse und Presharedkey gearbeitet.Der meiste Traffik läuft auf der Sonicwallseite im Netz: 192.168.5.0/24. Und genau nur diese Verbindung zu den Remotenetzen im Lancom ist gestört. Alle anderen Netzbeziehungen laufen ständig. Ode sagen mir vorsichtig so: Hier wurde bislang keine Fehler festgestellt.
Wenn der Tunnel händisch neu aufgebaut wird, dann hält das für ca. 6-7 Std. Diese Zeit entspricht aber nicht dem Erneuerungsintervall von 28.800s. Anschließend darf man wieder "Hand anlegen".
Was mich dabei stutzig macht ist folgendes:
In der Sonicwall kann ich für den gesamten Tunnel die Option "Disable IPsec Anti-Replay" aktivieren. Wenn man das dann abspeichert, funktioniert der VPN manchmal wochenlang tadellos. Bis der Fehler dann wieder auftritt.
Ab dann tritt das Phänomen wieder regelmäßig auf. Dann nehme ich in der Sonicwall wieder diese o.g. Option raus. Danach läuft das wieder wochenlang.Ich denke mal, dass diese Option mit diesem Fehler nichts zu tun hat. Ich tippe eher darauf, dass dieser Fehler durch eine Konfigurationsänderung erstmal weg ist. Das wird wohl Zufall sein.
Meine letzte Idee war, dass die Sonicwall mit der Firmware dieses Problem hat. Ich hatte aber, mit Rücksprache von Sonicwall, eine aktuelle, gut lauffähige Firmwareversion aufgespielt.
Aber daran lag es nicht.Ja, jetzt die spannende Frage:
Hat da jemand eine Idee?
-
Mir ist das nur aufgefallen, wenn Nutzer sich eine E-Mailadresse notieren. Da wird das gerne so notiert:
Vorname.Nachname@firma.de
Was die dort in Outlook nun genau eintippen, weiß ich nicht.
-
Am 19.1.2019 um 21:05 schrieb uweblaha:
Nun sehen meine Absender folgendermaßen aus:
vorname.nachname@Firma-Tätigkeit.de
Ich hätte aber gerne:
vorname.nachname@firma-tätigkeit.de
Ist das technisch gesehen egal , ob hier Groß- und Kleinschreibung verwendet wird?
-
vor 12 Stunden schrieb NilsK:
ch weiß nicht, von was für einem Kerberos-Passwort du sprichst. Vielleicht ein Missverständnis?
Hm, da bin ich mir selber nicht so sicher.
Ich habe gerade etwas tiefer den "Bauchschußthread" gesehen. Hier war wohl das gleiche Problem.
Hier noch mal das Zitat daraus:
Bauchschuß: krbtgt-Kennwort nicht mehr synchron... Lösung: kdc auf allen DCs außer dem PDC deaktivieren, dann alle außer dem PDC neu booten.
Ist das krbtgt-Kennwort das Gleiche, wie das Computertkennwort? Oder besser gesagt, redet man hier von der gleichen Sache?
-
vor 6 Minuten schrieb NilsK:
Lass die Replikation in Ruhe
Hab ich auch. Ich habe gerade mal nachgesehen. Jetzt ist dort auch ein Eintrag. Sieht gut aus.
Eine Frage noch:
Wie lange könnte man eine Seite komplett down lassen? Ich habe in den Metadaten gesehen, dass eine Aktualisierung des Kerebos-Passworts wohl alle 5 Min. durchgeführt wird.
-
Hier schien wohl dieses Problem die Ursache gewesen zu sein. Siehe hier:
-
So, jetzt bin ich weiter.
Wie es aussieht funktioniert das wieder. Die große Hilfe kam von hier:
In dem o.g. Beispiel ging es um 2 DCs. Ich habe dann von allen Vieren mir die Metadaten anzeigen lassen. Dort habe ich dann gesehen, dass die Kerberos-Passwörter von der Außenstelle deutlich älter, als die beiden in der Haupstelle waren.
Anschließend habe ich dann auf den beiden DCs von der Außenstelle, das o.g. Verfahren durchgeführt.
Nach einer Minute lief wieder alles.
Eine Kontrolle mit repadmin /showrepl zeigt bei allen DCs keine Fehler.
Meistens ist es ja so, wenn man vorher irgandwo etwas herumgeschraubt hatte, dass auf diese Sache sofort der Verdacht fällt. Ist ja meistens auch richtig, nur nicht in diesem Fall.
Hier war wohl die Offlinezeit der beiden DCs einfach zu hoch.
Noch eine abschließende Frage:
Bei der Kontrolle der NTDS-Settings ist mir bei dem DC-Paar in der Haupstelle aufgefallen, dass bei einem Server (DC-1) keine automatisch generierte Verbindung besteht. Auf dem anderen Server (DC-2) ist eine automatische Verbindung zum DC-1 vorhanden.
Wird das irgendwann noch wieder automatisch erstellt? Ich wollte das jetzt nicht manuell hinzufügen.
-
Was bedeutet Zeitlang? DC-1 und DC-2 waren ca. 5 Std. offline. Die anderen beiden DCs in der Nebenstellen waren jedoch immer an.
Nachtrag:
In der Zeit, wo die beiden DCs aus waren, habe ich in beiden Geräten eine neue Netzwerkkarte eingebaut. Nach dem Hochfahren des DC-1 fiel mir sofort auf, dass bei beiden die Windowsaktivierung futsch war. Das muss jetzt nicht unbedingt mit diesem Fehler zusammenhängen, nur ich vermute es schon fast.
Siehe auch hier:
-
Hier noch ein paar Ausgaben, die ich gerade erstellt habe.
Server-DC-1 und Serer-DC-2 stehen in der Haupstelle und die anderen beiden Server-DC-3 und 4 in der Nebenstelle.
Ausgabe repadmin /replmon auf Nebenstelle DC-3:
==== EINGEHENDE NACHBARN=====================================
DC=ForestDnsZones,DC=SUB,DC=FIRMA,DC=DESande\SERVER-DC-4 über RPC
DSA-Objekt-GUID: c24f5916-0819-463c-9a67-3cdb9bbefa72
Letzter Versuch am 2019-01-15 13:56:58 war erfolgreich.
Quelle: SUB\SERVER-DC-2
******* 5 AUFEINANDERFOLGENDE FEHLER seit 2019-01-15 13:11:03
Letzter Fehler: -2146893022 (0x80090322):
Der Zielprinzipalname ist falsch.
Namenskontext: DC=ForestDnsZones,DC=SUB,DC=FIRMA,DC=DE
Quelle: Sub\SERVER-DC-2
******* WARNUNG: KCC konnte diese REPLIKATVERKNPÜFUNG aufgrund eines Fehlers nicht hinzufügen.
Ausgabe repadmin /replmon auf Nebenstelle DC-4:DC=SUB,DC=FIRMA,DC=DE
Sande\SERVER-DC-3 über RPC
DSA-Objekt-GUID: 2b58a3ff-cae0-49b6-99ec-234893fb7905
Letzter Versuch am 2019-01-15 14:21:51 war erfolgreich
Ausgabe repadmin /replmon auf Hauptstelle DC-2:
DC=ForestDnsZones,DC=SUB,DC=FIRMA,DC=DE
SUB\SERVER-DC-1 über RPC
DSA-Objekt-GUID: c450d19c-1343-4e32-a8d5-e5ce37d4d636
Letzter Versuch am 2019-01-15 13:58:33 war erfolgreich.
Sande\SERVER-DC-3 über RPC
DSA-Objekt-GUID: 2b58a3ff-cae0-49b6-99ec-234893fb7905
Letzter Versuch am 2019-01-15 14:13:34 war erfolgreich.
-
Moin,
ich habe auf zwei DCs die folgende Fehlermeldung:
Der Kerberos-Client hat einen KRB_AP_ERR_MODIFIED-Fehler von Server "server-DC-2$" empfangen. Der verwendete Zielname war SERVER-DC-2$. Dies deutet darauf hin, dass der Zielserver das vom Client bereitgestellte Token nicht entschlüsseln konnte.
In der Hauptstelle stehen 2DCs, in der Nebenstelle stehen auch zwei DCs.
Zwischen den beiden zusammenstehenden DCs scheint die Replikation wohl zu stimmen. Zwischen der Haupstelle und Nebenstelle besteht das Problem.Wenn ich jetzt eine Verbindung von der Nebenstelle zu einem der beiden DCs in Hauptstelle einrichte dann bekomme ich diese Fehlermeldung. Diese sind dann nur den beiden DCs der Nebenstelle.
Auch ein REPADMIN /SHOWREPL zeigt auf den beiden besagten DCs Fehler.Hier scheint mit den SPS etwas nicht zu stimmen. Nur hier komme ich derzeit nicht weiter.
Wer hat eine Idee, wo ich nachsehen sollte? -
Moin,
ich habe oder besser gesagt, hatte hier folgendes Problem:
Es gibt hier eine Domänenumgebung mit 2 DCs (2008 R2). Weiterhin gibt es hier einen KMS Server (2012 R2). Auf diesem KMS ist der Key für Windows-Server 2019 hinterlegt.
Das lief lange Zeit ohne Fehler.Jetzt hatte ich bei beiden DCs die Netzwerkkarte getauscht. Nach dem Hochfahren der DCs stellte sich erst einmal heraus, dass bei beiden Geräten die CMOS-Batterie alle war.
Also Batterie gewechselt und dann einzeln hochgefahren. Anschließend hat sich gezeigt, dass bei beiden DCs die Windows-Aktivierung weg war. Ich nehme an, dass der Wechsel der Netzwerkarten schuld daran war.
Hier hatte sich wohl die Hardware zu stark verändert.Nun wurden beide Server nicht mehr vom KMS-Server aktivert. Ich konnte mir das erst einmal nicht erklären. Bis ich dann festgestellt hatte, dass der Threshold vom KMS-Server zurückgesetzt war. Er hatte also zu diesem Zeitpunkt nur 2 Anfragen.
Das reicht ja nicht aus, er benötigt dafür 5.Und das verstehe ich derzeit nicht, warum wurde hier der Threshold zurückgesetzt?
Dann ein weiteres Problem, welches ich derzeit nicht verstehe:
Manche Clients können nicht mehr drucken. Der Drucker ist auf einem DC installiert und dort per Freigabe und GPO für die Clients bereitgestellt.
Nachdem man dann bei den Clients ein GPUPDATE und Neustart durchgeführt hatte, funktionierte auch das wieder.Was könnte hier denn passiert sein?
-
Moin,
ich habe hier einige Notebooks von DELL, die ich mit einem Fernseher verbinden möchte. Mit einigen Geräten funktioniert das problemlos, jedoch mit zwei Geräten nicht.
Bei einem Gerät habe ich beiden Treiber (WLAN und Intel-Grafikadapter) auf den aktuellsten Stand gebracht. Das brachte aber keine Veränderung.
Mit dxdiag habe ich mir auf einem Gerät, welches funktioniert und bei einem Gerät, wo es nicht funktioniert erstellt.
Hier scheint aber zwischen in den wichtigsten Passagen kein Unterschied zu bestehen. Hier ein Ausschnitt:
Miracast: Available, with HDCP
Für den Intel Grafikadapter:
Miracast: Supported
Wenn man so nach Lösungen dazu sucht, dann können oft die falschen Treiber installiert sein. Seltsamerweise, bei den Notebooks, wo es funktioniert, sind tw. noch die alten Treiber von der Installation drauf.
Mir ist bei der Fehlersuche aufgefallen, dass die Notebooks mit folgenden Versionen funktionieren:
Windows 10, 1607 und 1703
Notebook mit den Windows Versionen 1803 und 1809 funktionieren nicht.
Das kann natürlich Zufall sein. Leider sind die Notebooks von der Hardware auch nicht alle gleich.
Hat noch jemand eine Idee, wo man noch suchen könnte?
-
Am 30.11.2018 um 15:52 schrieb DocData:
Der Name im Zertifikat passt nicht zum RADIUS.
Ja, das wars. Ich hatte wohl das richtige Zertifikat im IAS, jedoch war noch ein altes, falsches im Speicher. Und das Zertifikat war in der Richtlinie ausgewählt.
-
Da muss ich mal nachsehen. Ich werde dann Montag berichten.
-
Hallo,
ich habe eine WLAN-Verbindung mit Zertifikaten aufgebaut. Das Notebook ist in der Domäne und bekommt seine WLAN-Einstellungen per GPO. Mit einer zweistufigen PKI habe ich dafür ein Zertifikat bereitgestellt. Das Notebook hat das dafür erstellte Zertifikat und ein Eintrag in den Stammzertifiierungstellen vom ROOT-Zertifikat ist auch vorhanden.
Ich verbinde das Notebook mit dem WLAN. Jetzt erscheint die folgende Sicherheitsmeldung von Windows 10:
Verbindung weiter herstellen?
Wenn Sie "WLAN-Test" hier erwarten, können Sie bedenkenlos eine Verbindung herstellen.
Andernfalls handelt es sich möglicherweise um ein anderes Netzwerk mit demselben Namen
Zertifikatsdetails anzeigenIch stimme dem zu, anschließend bin ich mit dem WLAN verbunden.
Ist das normal, dass diese Meldung kommt oder ist hier noch was nicht richtig?
-
Moin,
ja das dachte ich mir gestern auch noch. Denn von oben kommt auch DHCP und dann haben die Clients keine IP-Adresse mehr. Dann hat sich das eh alles erledigt.
Ich habe in diesem Fall VRRP verworfen.
Danke für Antwort.
-
vor 8 Stunden schrieb DocData:
Aber ich befürchte für das, was du da wohl vorhast, ist VRRP nicht gedacht.
Sorry für die schlechte Erklärung. Ich habe davon mal eben eine Skizze gemacht. Ich hoffe, dass das aussagekräftiger ist. Aber ich denke auch schon fast, was du geschrieben hast, dass VRRP für diesen Fall nicht so gedacht ist. Aber ich bin mir halt nicht so ganz sicher.
Vielleicht nochmal die Frage:
Wenn die beiden Leitungen ausfallen, dann hätte ich auf den Aruba kein Routing zwischen den VLANs mehr.

-
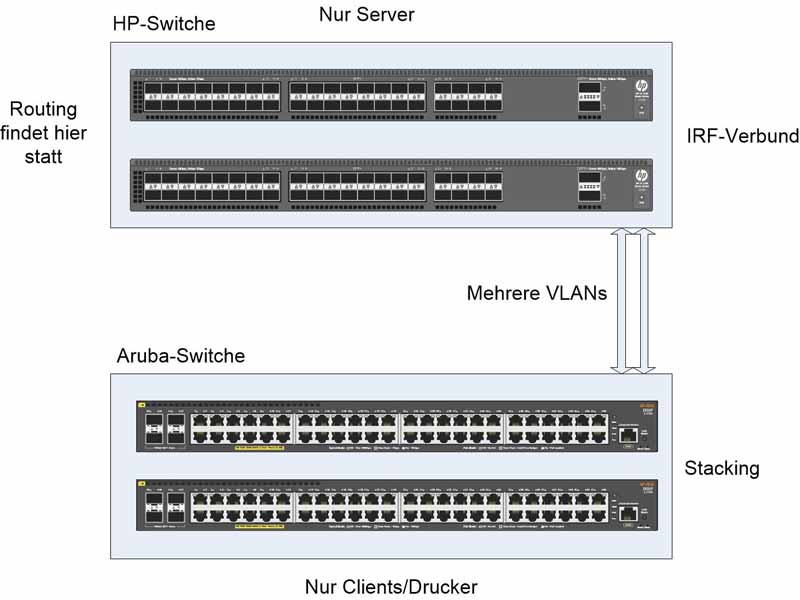
Moin,
ich habe zwei HP Core-Switche, die im IRF-Verbund sind. Weiterhin habe ich zwei Aruba Switche, die mit jeweiligen Stackmodulen zu einem Stack verbunden sind.
Zwei Leitungen (LACP) gehen vom IRF-Verbund zum Aruba-Stack. Demnach hätte ich hier ja nur 2 Switche zu betrachten, statt 4.Jetzt bin ich am überlegen, ob es hier Sinn macht, VRRP auf beiden Einheiten zu konfigurieren.
Würden die beiden Leitungen zwischen den Einheiten wegfallen, dann wäre ja auf beiden Seiten zwischen den VLANs noch ein Routing möglich.
Allerdings bezweifele ich, dass beide Leitungen gleichzeitig ausfallen könnten.Nun hatte ich VRRP auf beiden Seiten konfiguriert und auch getestet. So wie es aussieht, funktioniert das. Allerdings bin ich mir nicht sicher,
ob das hier nur per Zufall funktioniert. Stutzig wurde ich, wenn ich mir beim HP-IRF-Verbund den Status von VRRP anzeigen lasse:
Dort kann man den Zustand nicht vom Aruba-Stack sehen. Dort steht nur der Zustand vom HP-IRF-Verbund selber.
Auch beim Arubastack: Hier sieht man auch nur den Zustand von dem Aruba-Stack selber.Hier findet zwischen dem IRF-Verbund und dem Aruba-Stack kein Zusammenspiel statt.
Daher meine Frage:
Macht man das überhaupt so? Kann das so funktionieren? Und wenn es funktionieren würde, macht es in diesem Fall Sinn?
Auf dem beiden Core-Switchen hängen die Server und an dem Aruba-Stack eigentlich nur Clients und Drucker. -
vor 9 Minuten schrieb zahni:
Prüfe, ob der PDC-Emulator wirklich noch PDC-Emulator ist.
Dann:
Was ist hier
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Parameters
bei NTPSERVER und TYPE eingetragen?
Wenn ich hier w32tm /query /source eingebe, sehe ich den externen Zeitserver.
Moin,
um zu überprüfen, ob der PDC-Emulator noch wirklich der PDC ist habe ich folgendes unternommen:
netdom query fsmo
Ok, die Ausgabe stimmte so noch. Dann auf allen DCs mit RSOP oder GPRESULT überprüft, ob die eine GPO (wo der WMI-Filter ist) auch wirkt oder eben nicht wirkt. Sie zog nur bei dem PDC. Dahe meine ich, dass das noch stimmt.
Ist die Vorgehensweise richtig?
Dann zu den REG-Einträgen:
Auf dem PDC-Emulator selber stehen:
Bei dem Pfad
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Parameters
steht bei Ntpserver: time.windows.com,0x9 und bei Type: NT5DS.
Unter
HKEY_LOCAL_MACHINE\SYSTEM\SOTWARE\Policies\Microsoft\W32TIME\Parameters
steht bei NtpServer: 192.53.103.108 und unter Type: NTP
-
Nein, die sind alle auf Bleche. Jetzt habe ich mal etwas mit verschiedenen NTP-Servern experimentiert. Ich hatte bisher immer nur die IPs: 192.53.103.103 und 192.53.103.104 verwendet. Jetzt habe ich mal die 192.53.103.108 ausprobiert.
Jetzt hat sich das geändert:
Bei w32tm /query /source kommt:
192.53.103.108
bei w32tm /query /peers kommt:
Anzahl Peers: 1
Peer: 192.53.103.108
Status: aktiv
Verbleibende Zeit: 866.0000s
Modus: 1 (Symmetrisch aktiv)
Stratum: 1 (Primärreferenz - synchron. über Funkuhr)
PeersAbrufintervall: 10 (1024s)
HostAbrufintervall: 10 (1024s)
Wieder zurück auf eine alte IP, gabs den o.g. Fehler.
Die Uhr tickt auch wieder genau. Allerdings brauchte sie ein paar Minuten, bis die Uhr wieder richtig lief.
So ganz verstehe ich das allerdings nicht.
-
Moin,
bei w32tm /query /source kommt:
Local CMOS Clock
bei w32tm /query /peers kommt:
Anzahl Peers: 1
Peer: 192.53.103.103
Status: aktiv
Verbleibende Zeit: 991.0000s
Modus: 1 (Symmetrisch aktiv)
Stratum: 0 (nicht angegeben)
PeersAbrufintervall: 0 (nicht angegeben)
HostAbrufintervall: 10 (1024s)
WMI ist aktiv. In der GPO habe ich ja auch nichts verändert. Der PDC-Emulator selber bekommt seine Zeit nicht vom NTP-Server. Testweise habe ich mal auf dem PDC die Uhrzeit wieder richtig eingestellt. Anschließend ziehen alle anderen Mitglieder auch wieder die Zeit vom PDC. Das scheint noch so zu funktionieren.
Beim Befehl w32tm /resync kommt die Meldung:
Der Computer wurde nicht synchronisiert, da keine Zeitdaten verfügbar waren.
-
Hallo,
ich habe derzeit ein Problem mit der Zeitsynchronisierung per GPO.
Die GPO habe ich damals nach dieser Anleitung eingerichtet:
Das lief auch über die Jahre sehr gut. Jetzt geht die Uhr vom PDC etwas vor. Sieht so aus, als wenn er seine Zeit vom CMOS-Chip bezieht.
Ein Neustart des Zeitdienstes vom PDC brachte nichts. In der Firewall wurde auch nichts verändert. Hatte mal testweise einen Arbeitsgruppenrechner direkt mit dem NTP-Server synchronisiert.
Das funktioniert einwandfrei.In der GPO habe ich als Zeitserverver 192.53.103.103 oder auch mal pool.ntp.org eingetragen.
Hat jemand eine Idee wo man noch suchen könnte?
VPN Sonicwall - Lancom Problem mit Netzbeziehungen
in Windows Forum — LAN & WAN
Geschrieben
Nun habe ich heute die Version 10.20 RU2 aufgespielt. Nachdem der Router seinen Neustart beendet hatte, hatte ich gleich gesehen, dass das nicht Erfolg führte. Ich musste also beim Tunnelaufbeu bei 2 Netzen wieder nachhelfen.
Jetzt bin ich mir nicht sicher, ob ich dich richtig verstanden habe: Besteht das Problem im VPN immer noch bei der aktuellen Version oder redest hier von VRRP?