moma
-
Gesamte Inhalte
8 -
Registriert seit
-
Letzter Besuch
Fortschritt von moma
")





-
Danke euch allen für die Informationen, kam jetzt zu einer Lösung und auch zu einem super Tipp für alle (wer es noch nicht weis). Wenn man mehrere Tabellen joined, dann sollte man, wenn möglich das gleiche Joinkriterium verwenden, z.B. bei allen joins z.B. eine Inventarnummer.
-
Ok mittlerweile kam ich von 4-5 Ladesekunden der Abfrage, die ich optimieren will auf 2 Sekunden ladezeit (in der Datenbank) gekommen. Das Ziel wäre eigentlich schon 1 Sekunde Ladezeit. Ok also werde ich mal alles mit UNIQUE auch probieren. Gute Idee danke.
-
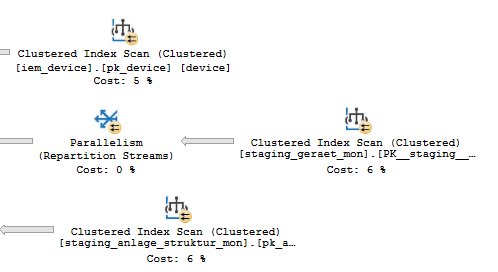
Schön langsam bin i am verzweifeln oder i mach nu irgendwas falsch. Weil einen clustered Index kann i nimmer setzen (is ja der PK). Mit nonclustered Indexe bekomm i aber das beim Execution Plan nicht weg. Das ist das häufigste was in dem Plan vorkommt (immer 6% für clustered Index Scan von unterschiedlichen Tabellen) Wie muss ich vorgehen, damit solche Sachen im Plan verschwinden? Hier steht ja eigentlich ein nonclustered Index mit 2 Spalten und einem INCLUDE(anlage_nr) (Keine Ahnung was das noch bedeutet)

-
@mwiederkehr Ok danke mal für die Infos, ok, das bedeutet wenn was von einer anderen View angezeigt wird, muss ich den Index auf die andere View setzen, die verwendet wird. Ja mein zweiter Weg, sollte die Performance nicht "gut genug" werden, nach dem Setzen der Indizes, dann werde ich täglich in einer Procedure diese Daten (In diesem Fall eine Störungsliste) in einer Tabelle ablegen (und täglich MERGEn)
-
Hallo Leute, ich habe jetzt genauere Infos, was ich benötige und ein Paar Fragen dazu. Vlt. zuerst mal die Ausgangssituation: 1) Ich habe eine View, die auch eine Andere View benötigt und diese mit ca. 5 Datenquellen (Tabellen) verknüpft derzeitiger Plan 2) Da in diesem Fall eine Materialized View nicht verwendet werden kann muss ich vorerst probieren, die Performance durch Indizes zu verbessern, dazu würde ich folgendermaßen vorgehen (Nachgelesen im Internet) CREATE UNIQUE CLUSTERED INDEX IX_ErrorList_Selfread ON Beispiel_View ( [serialnumber] ,[anlage_nr] ,[plz] ,[ort] ,[strasse] ,[haus_nr] ,[haus_nr_zusatz] ,[lastSR] ,[ableseeinheit] ); Und natürlich darf ich das Schemabinding auf die enthaltenen Views nicht vergessen. Meine Frage dazu ist noch: Muss ich die Indizes auch auf alle Tabellen oder andere Views setzen, oder reicht dies, diese auf die verwendete View zu setzen. Also wie würde ich eine bestmögliche Performance erhalten? (Beachtet wird die Eindeutigkeit bei den Spalten wie z.B. die Seriennummer, die Anlagennummer usw. in diesem Fall) Ist das der "richtige" INDEX, den ich verwende? Oder wie würdet ihr vorgehen? DANKE. und danke für die Links, die halfen dabei sehr.
-
Super, bei diesen Links von euch, werde ich sicher was finden und werde mich mal hineinlesen =) Ok was mir jetzt aufgefallen ist, bei den links, die ihr mir sendetet, hier sehe ich wie ich eine View mit Indizes usw. erstelle. Ok das verbessert sicher die Performance aber was ich suche ist eine View, die sich nur einmal am Tag aktualisiert zu dem Zeitpunkt, den ich angebe. Weil dann ist das wie eine befüllte Tabelle was so vorhanden ist und somit die Performance perfekt. Ok also da sollte ich eh Indexes setzen, hab ich dann falsch verstanden, denn das mit den täglichem Laden einer View funktioniert eh wie ihr sagtet nur auf Azure
-
Danke mal für die Informationen, werde ich mir ansehen, nur sehe gleich beim Link es geht um materialized views, die ich nicht verwenden kann und dann hörte ich von meinem DB-Admin, dass es bei Oracle materialized views sind und bei SQL clustered index views. Und deshalb suchte ich nach solchen Statements. Die Lösung ist laut ihm, eine View zu erstellen, die nicht immer neu geladen wird, nachdem durch eine Web-App eine Ansicht geöffnet wird, sondern eben eine View die sich täglich um 6 Uhr aktualisiert und dann ist die View immer sofort offen und die Performance läuft. Die Dauer ist deshalb vorhanden, weil ich schon sehr viele Tabelle (Daten aus untersch. Systemen) verknüpfen muss um alle notwendigen Informationen zu erhalten. werde mir mal die Links von dir ansehen.
-
moma ist der Community beigetreten
-
Guten Tag, ich hätte eine Frage über Datenbankviews, die ich noch nie verwendete => Materialized Views. Auf dem SQL Server werden diese clustered indexed views genannt und das Ziel dadurch ist, bestmögliche Performance zu haben. Denn man lässt diese Ansicht dann eben nur so oft wie notwendig aktualisieren, bei mir wäre das einmal um 6:30 morgens. Da ich mit solchen Views bis jetzt noch nichts zu tun hatte, jetzt jedoch die Wartezeiten schon ca. 3 Sekunden lang sind beim Laden einer Ansicht, hätte ich folgende Fragen: 1) Wie ich das im Internet fand, muss man einen Unique Clustered Index auf eine bereits vorhandene Tabelle/View erstellen: CREATE UNIQUE CLUSTERED INDEX UCIX_vCustomerSalesInfo ON iem_dashboard.iem_customerInfos(CustomerID, SalesOrderID, ProductID) 2) anschließend gibt es ein Update Statement wo man vermutlich die View Aktualisiert, verstehe jedoch das SQL Statement nicht update Sales.SalesOrderHeader set OrderDate= CAST('2010-08-24' AS DATETIME) where SalesOrderID > 1; Und ich würde es deshalb nett finden, wenn mir wer genau sagen kann, wie ich da vorgehe. Views sind bereits vorhanden und was muss ich schritt für schritt machen, wo habe ich schon richtige Informationen und was fehlt ev. noch? GROßEN DANK!