notimportant
-
Gesamte Inhalte
28 -
Registriert seit
-
Letzter Besuch
Alle erstellten Inhalte von notimportant
-

Veeam Restore Issue auf RODCs - Inkonsistente ntds.dit
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Trotzdem Danke für die Rückmeldung. MS Support ist noch überfordert, mal sehen, ob da noch was kommt. Ich kann ja kurz nachberichten, falls es interessant wird. Hauptsache nichts kumulatives, die Inkonsistenzen können wir ja auflösen, da wir genau wissen, was nicht passt. -
Veeam Restore Issue auf RODCs - Inkonsistente ntds.dit
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Mittlerweile habe ich die Vermutung, dass der Restore mittels VEEAM nicht die Ursache der Probleme ist, sondern der Impact durch die vorherige große Löschaktion (Diese war geskriptet). Die 5-stellige Anzahl an Nutzern waren natürlich in diversen Gruppen Mitglied. Während der Löschaktion loggten die Writable-DCs diverse 1955 und einige 1083. Auf den ersten Blick zwar verschwindend gering im Vergleich zur 5-stelligen Anzahl an Löschungen, aber eben über die Umgebung hinweg. War zuerst nicht aufgefallen, da wir uns auf den Restorezeitraum konzentriert hatten. Hat jemand Erfahrung mit einem solch großen Delete-Impact? Wenn im großen Stil Links und Link-Tables angefasst werden sieht das MS auch kritisch bezüglich der Performance replication-failures-delete-active-directory-objects Sind zwar ja nicht direkt die Gruppenobjekte, diese müssen aber ja in großem Stil angefasst werden, da die Forward-Links gelöscht werden müssen. -
Veeam Restore Issue auf RODCs - Inkonsistente ntds.dit
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Ok, zumindest die IFM-RODC-Diskrepanz ist genau so zu erwarten. (Wichtiges Detail ist vielleicht noch, dass der AD Papierkorb nicht aktiv ist und VEEAM die Tombstones wiederherstellt.) Wird ein AD-User gelöscht, verschwindet auch sein ABSENT-Entry der Gruppe, der normalerweise 180 Tage Tombstonelifetime vorgehalten wird. VEEAM restoret nur die postitiven Gruppenmitgliedschaften neu, da es sich einfach die Mitgliedschaften merkt. Mit einer "normalen" neuen Transaktion, neue USN, neue Versionnumber 1 in den Metadaten. Exakt wie ein normaler administrativer Vorgang "Gruppenmitglied hinzufügen". Somit kann die Löschung nicht mehr repliziert werden, da die ABSENT-Daten unwiderbringlich verloren sind. Erklärt natürlich noch nicht das Fehlen der restoreten Group Member auf diversen RODCs. Die Ursprungs-USNs sind auf den RODCs, wo sie eingetragen sind, korrekt, nachvollziehbar und mit den Writables identisch. Ist mir noch ein Rätsel. -
Veeam Restore Issue auf RODCs - Inkonsistente ntds.dit
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Guten Morgen, nein, leider gar keine Schulungsumgebung Es werden keine RODCs zurückgespielt oder wiederhergestellt. Das sind ganz einfach zusätzliche Read-Only-DCs in einer separaten Site. Die tun ja nicht weh, können an der Datenbank nichts verändern, aber man kann die Inhalte und Metadaten vergleichen. Was in diesem Fall wie oben beschrieben interessant ist, da wir unter anderem auch IFM-Installationen vornehmen. Grüße -
Veeam Restore Issue auf RODCs - Inkonsistente ntds.dit
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Guten Abend, ja die Umgebung ist nicht gerade klein und im hohen Maße verteilt. Ein RODC ohne IFM ist fertig, d.h. ntds.dit zu 100% frisch von den Writable DCs. Dieser zeigt dann das erwartete Bild. Datenbank identisch mit den aktuellen Writables. Entweder hat VEEAM Fehler gemacht in der Masse, oder es gab Probleme in unserer Umgebung bei der Replikation. Das diverse Bild über die Umgebung erschließt sich mir aber trotzdem noch nicht. Der Restore ging von einer einzelnen Quelle aus. Das kann eigtl. ja nicht passieren. Auf jeden Fall vielen Dank für die Hinweise und Unterstützung am Wochenende. Der Vergleich hat mich jedenfalls gedanklich/theoretisch nochmal ein gutes Stück weiter gebracht. Schönen Abend -
Veeam Restore Issue auf RODCs - Inkonsistente ntds.dit
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Guten Morgen, gute Idee, habe ich über Nacht mal installiert. Interessant. Wir deployen RODCs über eine IFM-Installation. Betroffene Nutzer haben auf einem neuen IFM-RODC mit ntds-Datum von vor der Löschaktion jetzt tlw. zu viele Gruppen. Müsste man in den Metadaten einer Gruppe eigentlich nicht sehen, dass Nutzer x in dieser nicht mehr vorhanden ist, wenn VEEAM korrekt die Mitgliedschaften wiederherstellen wollte? Dieser Eintrag verschwindet ja bei Löschen eines Objekts, solange das Objekt existiert, benötige ich diesen Eintrag doch, um die Information zu replizieren? Grüße -
Veeam Restore Issue auf RODCs - Inkonsistente ntds.dit
notimportant hat einem Thema erstellt in: Active Directory Forum
Hallo zusammen, ein gutes neues 2025, wie immer habe ich ein interessantes Phänomen auf unseren Read Only DCs. Bei einer größeren Restoresession (knapp 5-stellig) aufgrund einer unbeabsichtigten Löschaktion mit VEEAM (Application Aware) von Userobjekten (kein DC-Restore, nur Userobjectrestore) haben wir das Phänomen, dass die Gruppenmitgliedschaften auf den ReadOnly DCs inkonsistent repliziert wurden. Die Writable DCs haben sowohl den Forward (member) als auch Backlink (memberOf) der Gruppenmitgliedschaften sauber in der Datenbank. Die RODCs haben jedoch ca. im 10%-Bereich die Wiederherstellung nicht ordentlich repliziert. Editieren wir jetzt die Group-Memberships, replizieren sich die Änderungen sauber durch. Die Lücken aus den Restoresessions bleiben bestehen. Die Metadaten der RODCs zeigen, dass die Nutzer aus den Gruppen entfernt wurden. Die Logs sind frei von jeglichen Replikationsproblemen und die Replikation der gesamten Umgebung ist zum Status quo einwandfrei. Die USNs zeigen, dass VEEAM korrekt restoret. Erst der Nutzer, dann die Gruppe. Der komplette Restore wurde auf einem einzelnen Writable DC durchgeführt. Die fehlenden Mitgliedschaften sind nicht gleichverteilt über die RODC-Landschaft. Auf jedem RODC fehlen andere User in anderen Gruppen. Tickets sind zwar offen, aber hat jemand vielleicht eine Idee, was speziell dieses Szenario verursachen könnte? -
Password Replication Tab bei User/Computer-Objekten in der ADUC
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Sodala. Aus gut unterrichteter Quelle kann ich berichten, dass hier das Attribut msDS-RevealedDSAs zu sehen sein müsste. Dieses war auch bis 2008R2 in der GUI zu sehen, aber ist auf dem Wege zu 2012 verschütt gegangen und seitdem nicht wieder in der GUI aufgetaucht ; ) -
Password Replication Tab bei User/Computer-Objekten in der ADUC
notimportant hat einem Thema erstellt in: Active Directory Forum
Hallo zusammen, bisher habe ich unsere PRP ausschließlich über die DC-Objekte und Skripte gemanaget und mir ist nie bewusst aufgefallen, dass die User und Computerobjekte ja auch einen Reiter "Password Replication" besitzen. Weiß jemand welches Attribut hier angezeigt werden (müsste)? Ich kann mir nämlich einen beliebigen User herauspicken dessen PW-Hash definitiv auf einem RODC zwischengespeichert ist, aber das Feld ist leer. Von der Beschreibung her müsste es eigentlich msDS-RevealedDSAs (Backward link for ms-DS-Revealed-Users. Identifies which RODC holds that user's secret.) sein. Das Attribut ist für den User auch befüllt. Hier: TechNet: active-directory-attributes-in-the-aduc-gui-tool und hier: selfadsi: user-attributes-w2k8 wird allerdings behauptet es wäre das Attribut msDS-AuthenticatedAtDC (The attribute contains a list of computer objects, corresponding to the RODCs at which the user or computer has authenticated). Auch das ist befüllt für den obgen User. Wieso ist das Feld leer? Hier hatte mal jemand dasselbe Problem beschrieben, aber auch ohne Lösungsidee. Ist das vielleicht ein Anzeigefehler, oder wurde das Feld nur in 2008 genutzt?
-
Clients senden DNS Dynamic Update Pakete nicht zuverlässig
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Hallo, Genau. Das Bild kann ich auch genauso sehen (Die KRB5-Frames sind ausgeblendet): Ich verstehe nur nicht, weshalb ein und derselbe Rechner auch das hier macht. Ich würde erwarten, dass ich immer obiges Bild erhalte. Übersehe ich etwas? Im Testlab erhalte ich immer untenstehendes Bild (aber auch hier sind only-secure-Updates aktiviert). Oder eben die Dynamic Update - Pakete gar nicht auftauchen. Beim Aushandeln mit dem DHCP sieht dann noch immer alles gut aus: Aber es tauchen keine Dynamic Update Pakete auf. Ist definitiv deaktiviert. Grüße
-
Clients senden DNS Dynamic Update Pakete nicht zuverlässig
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Per default nicht, das haben wir aber bei den traces aktiviert und mitlaufen lassen. Leider so gar nichts ungewöhnliches. -
Clients senden DNS Dynamic Update Pakete nicht zuverlässig
notimportant hat einem Thema erstellt in: Active Directory Forum
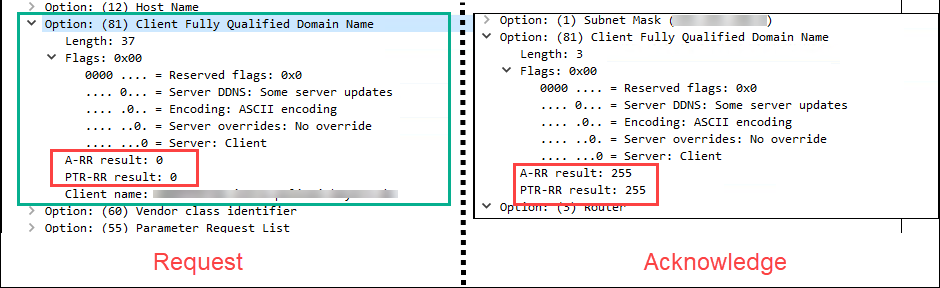
Hallo zusammen, ich habe mal wieder ein sehr spezifisches Problem. Und zwar haben wir in unserer Umgebung Probleme mit den automatischen Updates der DNS-Records. Nur in Kürze die notwendigen Eckpunkte: AD integriertes DNS Clients registrieren ihre A-Records selbst, die Reverseeinträge übernimmt der DHCP (also keine Option 81, sondern Standard) Nichtaktualisierungsintervall 7 Tage + Aktualisierungsintervall 7 Tage ... danach Scavenging der Records Hat jahrelang funktioniert, es wurde keine wissentliche Änderung gerade an solchen Kernfunktionalitäten vorgenommen, jedoch seit dem Herbst gibt es Probleme mit den automatischen Aktualisierungen. D.h. die DNS-Records vieler Clients altern aus dem DNS raus und werden vom Scavengingprozess gelöscht, obwohl diese Rechner: per DHCP versorgt werden täglich neugestartet werden Meines Wissens muss ein Client ja bei Neustart, wenn seine DHCP-Lease erneuert wird ein Dynmaisches DNS Update versuchen. Und gerade das scheinen unsere Clients zum großen Teil nicht mehr zuverlässig zu senden. Wir haben keine GPO bzgl. RegistrationRefreshIntervall o.ä. gesetzt. Die "üblichen" Verdächtigen "primäres Domain Suffix" usw. sollten alle als "passt" angehakt sein. Ich kann folgende Szenarien beobachten, erstellt unter der Zuhilfename einer großen Anzahl von Traces auf verschiedenen Clients: Szenario 1: "Alles OK" Der Client sendet einige Sekunden nach Konfiguration der NIC die folgende Paketreihenfolge: SOA-Anfrage, SOA-Antwort, DNS-Update-Anfrage, DNS-Update-Refused, TKEY-Negotiation, DNS-Update-Anfrage, DNS-Update-Success. Ganz brav, wie es MS hier etwa beschreibt: Secure Dynamic Update Szenario 2: "Keine TKEY Negotiation" Der Client sendet folgende Paketreihenfolge: SOA-Anfrage, SOA-Antwort, DNS-Update-Anfrage, DNS-Update-Success. Es erfolgt keine TKEY-Negotiation. Das sollte doch eigentlich nur passieren, wenn keine Secure Updates verwendet werden. Diese sind aber auf allen DNS-Servern als zwingend konfiguriert. Szenario 3: "Gar nix passiert" Der Client sendet keine DNS-Update-Pakete. Gar nicht. Das sollte, wenn ich es richtig verstehe, definitiv nicht vorkommen. Erklären kann ich es mir nicht. Solche Clients kann ich auch durch Änderung der Richtlinien (explizit DynUpdates aktivieren, RegistrationRefreshIntervall auf fixe 30 Min setzen) nicht dazu bewegen bei Neustarts zuverlässig die Updatepakete zu senden. Anmerkungen zu 1,2,3: Die Szenarien sind nicht fix auf einen Client beschränkt. Es gibt zwar Clients die relativ zuverlässig in Szenario 3 sich bewegen, aber eine große Anzahl der untersuchten Rechner sendet eben mal ein DNS-Update-Paket und eben mal nicht. Das ist über Modellvarianten brav verteilt. Es sind ca. 10-20% der Clients (ca. 3 -7.000 von 30.000) immer betroffen, wir sind ab Sommer/Herbst großflächig auf 20H2 migriert. Die Auffälligkeiten sind zusammengefallen, aber eine logische Verbindung konnte ich noch nicht herstellen. Szenario 2b: "Test Lab" In einem Testlab (DC auf Server 2022, alles ziemlich default) sendet ein Client zuverlässig, d.h. immer zu 100%, kurz nach seinem neuen DHCP-Lease seine DHCP-Update-Pakete. Diese allerdings auch immer ohne TKEY-Negotiation. Frage 1: Hat jemand irgendeine Idee, wo wir noch ansetzen könnten? Ich denke das ist eine Kernfunktionalität des DHCP-Client-Services. Keine Idee, wo man das kaputtkonfigurieren sollte. Frage 2: Kann jemand das seltsame TKEY-Negotiation-Verhalten erklären? Müsste das nicht immer auftreten? Oder ist hier die MS-Doku veraltet? Viele Grüße notimportant -
RODC - Vertrauensstellung - PRP Policy
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Genauso wollen wir das auch im Fall des Falles handhaben. Das tägliche Leeren und Neubefüllen der Gruppen hat(te) historische Gründe in der Organisationsstruktur. Das stellen wir gerade ab, die Clients und Nutzer bleiben nun dauerhaft (also ohne temporären Ausfall, dauherhaft war das vorher auch) in der PRP-Allow drinnen. Hier techcommunity.microsoft.com wird in einem Nebensatz aber immerhin genau mein Problem erwähnt: Das beschreibt zumindest genau das Bild, das ich sehe. Warum ich das durch das Löschen PRP-Mitgliedschaft provozieren kann erschließt sich mir aber noch nicht. PrtQry-Log gegen den RWDC sieht m.E. sauber aus. Vielleicht sollte ich mich auf Firewall/Netzwerk/AV konzentrieren. Ist wohl aber wirklich zu speziell für ein Forum. Danke Grüße PortQryLog.txt -
RODC - Vertrauensstellung - PRP Policy
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Stimmt. Die Tickets wären aber immer mit dem Domain-krbtgt-Account signiert, wenn ich es richtig verstehe. Der RODC guckt sich den Request immer an und prüft, ob er das Passwort in seiner lokalen Datenbank hat. (Und frägt auch jedes mal nach, ob er das PW nicht repliziert bekommt? Und ein beschreibbarer DC prüft die PRP jedes mal?) Und ich frage mich, ob genau an diesem Punkt vielleicht etwas schiefgeht, wenn der Rechner kurzfristig aus der PRP fliegt. Wir haben strikt einen RODC pro Site. Dadurch, dass das Problem über einen längeren Zeitraum sehr sporadisch auftritt, verteilt über alle Standorte, schließe ich die üblichen Verdächtigen wie Zeitabweichung usw. aus. Der Dreh mit den PRP-Gruppen war eher Zufall, lässt sich aber wunderbar reproduzieren : ) -
RODC - Vertrauensstellung - PRP Policy
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Verzichten in dem Sinne von "Tausch durch beschreibbare DCs" würde ich jetzt persönlich verneinen, da ich es durchaus als legitimen Grund sehe bei unserer Zweigstellendichte im dreistelligen Bereich Read Only Replikas zu nutzen. Ob man jetzt einen DC unbedingt überall haben möchte aus Gründen der Ausfallsicherheit... Darüber kann - und wird - man sicherlich diskutieren. Die Verwirrung um das aktuelle Phänomen behebt das allerdings nicht. Wie gesagt, das ist nicht mal im Ansatz ein Deal-Breaker für das aktuelle Design. Eher mal wieder die Neugierde eine fachliche Kuriosität aufzuklären : ) -
RODC - Vertrauensstellung - PRP Policy
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Ich wusste, dass diese Frage kommt : ) Ja, wir haben Interesse daran, dass ein ggf. kompromittierter RODC nicht die Passwörter der ganzen Umgebung preisgibt. Und das Design stammt im Prinzip aus der Feder von MS selbst : ) Die RODCs in der Fläche stehen nun nicht in 24/7 betreuten Rechenzentren wie es die beschreibbaren DCs tun. Oberste Priorität beim Design war, dass bei Ausfall der WAN-Leitungen ein Arbeiten in den Zweigstellen weiterhin gewährleistet ist, bei gleichzeitigem Schutz des kompletten Unternehmens-ADs. Dazu werden die PRPs mit den Benutzer- und Computerkonten befüllt und teilweise sogar vorab gecachet (wichtige Service Accounts beispielsweise). Das funktioniert soweit alles prächtig. Aus historischen Gründen wurden die Gruppen mit den Benutzern und Computern in der PRP-Liste der RODCs turnusmäßig geleert und neu befüllt, was nicht ideal geskriptet wurde und in einem Gap resultierte, in der die Clients temporär nicht in der PRP-Liste stehen. Meine Vermutung ist, dass Clients zu genau diesem Zeitpunkt die Vertrauensstellung verlieren, wenn die PRP-Gruppen geleert und neu befüllt werden und ein Client in den turnusmäßigen 30-Tage-PW-Account-Erneuerungsmodus rutscht. Was ja ein Aufeinandertreffen von vielen Zufällen bedingt. Genau dieses Verhalten kann ich reproduzieren, indem ich einen Client, der bereits dem RODC bekannt ist ( = er ist in einer Gruppe im Reiter Password Repl. Policy eingetragen, meinetwegen seit Monaten) absichtlich aus der PRP-Liste lösche, wenn er in den 30-Tage-Turnus läuft. Das Verhalten der Befüllung PRP-Gruppen zu ändern ist nicht das Problem. Mich würde der Grund für das Verhalten der Clients interessieren, ob es sich evtl. um einen Fall handelt, den Microsoft nicht im Design bedacht hat. Ich sehe drei Fälle im Konstrukt DC (Site A) -> RODC (Site B) -> Client (Site B). [Site B hat nur RODCs] Fall A: Client + User stehen nicht in der PRP jegliche Authentifizierung läuft über den beschreibbaren DC Fall B: Client + User stehen in der PRP bis auf die initiale Authentifizierung läuft die normale Authentifizierung über den RODC Fall C: User steht in der PRP + Client steht nicht mehr in der PRP -> gibt es hier irgendeine Konstellation, die den PW-Renewal-Prozess bricht? Nach 10-maligen Lesen von Desmonds AD komme ich für den Spezialfall auf keine befriedigende Lösung: Ich lösche den Client aus der PRP-Liste Innerhalb der normalen AD-Replikation "löscht" der RODC die lokale Kopie des Passworts. (Ja?) Der Client kontaktiert den RODC (Tut er das noch? Oder kann er mit dem RODC keinen Secure Channel mehr aufbauen, da der RODC den PW-Hash als null markiert?) Egal, was bei (3) passiert, entweder über den RODC oder direkt durch den Client erreicht der Request mMn den beschreibbaren DC. Der beschreibbare DC updatet das Computerobjekt und schickt das OK an den Client direkt oder über den RODC. Das "OK" müsste am Client ankommen und das neue Computerpasswort als aktiv gesetzt werden. Ob der RODC jetzt das Passwort repliziert (RWDC checkt PRP mit Ja) oder nicht (RWDC checkt PRP mit Nein) sollte doch keine Rolle spielen... Irgendwo muss in der "Provokation" des Falles die Erklärung liegen. Vielleicht ist das alles einfach zu speziell. In dem Fall wäre mein nächster Schritt den o.g. Spezialfall zu reproduzieren und auf dem Client mal einen Netzwerktrace mitlaufen zu lassen... Grüße -
RODC - Vertrauensstellung - PRP Policy
notimportant hat einem Thema erstellt in: Active Directory Forum
Hallo in die Runde, ich bräuchte eine zündende Idee, da ich momentan nicht weiterkomme. Unser AD besteht aus einer sternförmigen Netzwerkstruktur mit zentralen beschreibbaren DCs und RODCs in der Fläche (RODC, da keine 24/7 Anwesenheit in den Zweigstellen). Wir haben seit einiger Zeit das klassische Problem, dass Rechner die Vertrauensstellung zur Domäne verlieren. Bei einer 5-stelligen Anzahl an Rechnern ist es zwar lediglich ein kleines Grundrauschen, aber doch immer wieder nervig, da man sich an das jeweilige System lokal hinsetzen muss. Ich habe versucht das Problem so weit es geht einzugrenzen (Es sind keine Spezialfälle wie Klone, Snapshots usw. dabei) und sehe einen Zusammenhang mit unserer PRP-Policy auf den RODCs, da ich das Problem folgendermaßen reproduzieren kann: Ein Rechner ist im normalen 30-Tages-Turnus an der Reihe sein Maschinenpasswort zu erneuern. Auf den RODCs des jeweiligen Bereiches sind User und Computer in der jeweiligen PRP-Policy eingetragen. Entferne ich den Rechner aus der PRP-Policy und lasse ihn in den automatischen PW-Wechsel laufen verliert er nachvollziehbar die Vertrauensstellung zur Domäne. Der LastPasswordSet-Wert beim Computerobjekt im AD bleibt auf dem „alten“ Datum. Im Pfad HKEY_LOCAL_MACHINE\SECURITY\Policy\Secrets\$MACHINE.ACC sehe ich, dass die Werte CupdTime und OupdTime angefasst wurden mit dem Zeitstempel des Vertrauensstellungsverlustes, daher gehe ich davon aus, dass der Mismatch zwischen dem im AD gespeicherte Computerpasswort und dem lokal gesetzten Passwort auf dem Client daher rührt, dass das Passwort auf dem Client geändert wurde, nicht aber im AD. Vielleicht ist das ja alles normal, aber ich bekomme den Hintergrund nicht ganz zusammen. Soweit ich es verstanden habe funktioniert die initiale Anmeldung wie folgt (MS Docs): Client etabliert Netlogon SecureChannel zum RODC RODC forwarded das zum DC DC gibt die Kerberos Authentification zurück an den RODC RODC repliziert das PW (wenn er denn darf) RODC gibt die Authentifizierung an den Client Das sollte doch bei der PW-Erneuerung ähnlich ablaufen: Client etabliert SecureChannel zum RODC und will sein PW erneuern RODC gibt das an den DC weiter DC sagt OK und gibt die Bestätigung an den RODC RODC gibt die Bestätigung an den Client FALLS der Client in der PRP steht repliziert der RODC das PAsswort von einem DC in seine lokale Datenbank. (Wenn nicht dann eben nicht. Ansonsten besteht dch kein Unterschied?) Client macht jetzt erst den Haken an sein Passwort Und der Client ändert doch sein Passwort lokal nur auf den von ihm neu generierten Wert, wenn er von einem DC das OK dazu bekommen hat. Ansonsten verwirft er die Änderung. Mir ist nicht klar, wie mein Bild oben zustande kommt. Auch wenn ein Client nicht mehr in der PRP-Policy eingetragen ist, sollte doch ein PW-Wechsel keine Probleme bereiten, da er dann mit einem beschreibbaren DC reden sollte. Oder gibt es eine Abhängigkeit, wenn er bereits eingetragen _war_, dass der RODC das Passwort noch hat und Probleme bereitet? Die Probleme die bspw. hier (adsecurity.org) beschrieben werden... sind doch so nicht korrekt? Das Konstrukt funktioniert doch auch mit DC+RODC+keine PRP. Vor allem Satz 2 ist doch Käse. Der RODC holt sich doch das upgedatet AD-Objekt vom schreibbaren DC per RSO? Auch hier (active-directory-faq.de) Das sollte doch grundsätzlich nicht das Problem sein. Vielleicht kann jemand Licht ins Dunkel bringen : ) Grüße -
Shared Folder umbenennen zerschiesst ACL
notimportant antwortete auf ein Thema von notimportant in: Windows Server Forum
Vielen Dank für den Hinweis. Das war grob im Hinterkopf vorhanden, ist hier aber perfekt beschrieben und kommt sofort ins Einsteigerhandbuch! Den Umweg den Explorer anzupassen kannte ich so noch nicht. Auch interessant. Vielen Dank für die Antworten und Tipps. Haben sehr weitergeholfen! Grüße -
Shared Folder umbenennen zerschiesst ACL
notimportant antwortete auf ein Thema von notimportant in: Windows Server Forum
Dass der Explorer Probleme hat ist bei uns ja durchaus bekannt und dass das Nutzen remote über UNC-Pfad bspw. sinnvoller ist. Das Ausmaß der Auswirkungen bei diesem spezifischen Fall ist aber schon erstaunlich und als Defaultfall ohne Rückmeldedialog schon arg ungünstig... Aber was heißt Explorer (gar) nicht verwenden? Berechtigungstools sind bspw. im Einsatz, wenn ich aber einen einzigen neuen Ordner in der Unterstruktur anlege muss/(will) ich ja nicht zwingend die Powershell bemühen. Als alternative File Explorer zeigt etwa der Total Commander das obige Verhalten nicht, qDir wiederum schon. Gibt es für den "Browsen, Klicken und Anlegen"-Fall einen anderen Best-Practice-Ersatz? Bin für Empfehlungen immer sehr dankbar. Grüße -
Shared Folder umbenennen zerschiesst ACL
notimportant hat einem Thema erstellt in: Windows Server Forum
Hallo zusammen, ist das folgende Verhalten unter einem Standard-Windows-Fileserver immer (noch?) Standard? ich habe eine Ordnerstruktur Ordner1\Ordner2\Ordner3 Auf "Ordner1" setze ich eine beliebige NTFS-Berechtigungsstruktur Ordner1 gebe ich als \\Servername\Freigabename frei. Ändere ich jetzt den Namen des freigegebenen Ordners lokal auf dem Server mit der explorer.exe von "Ordner1" in "Ordner4711" ohne die Freigabe vorher zu beenden passieren zwei Dinge: die Freigabe wird gelöscht... Logisch Die ACL auf Ordner1/Ordner4711 wird gelöscht und komplett durch eine ACL mit Admin/Admingruppe/System ersetzt und natürlich nach unten weiterverebt. (der gleiche Vorgang mit einer elevated Powershell + Rename-Item sieht schon wieder anders aus, da bleiben die ACLs erhalten) (Beende ich die Freigabe vorher funktioniert alles problemlos) Ist das wirklich das Standardverhalten? Fühlt sich schon arg buggy an. Grüße -
Mythen zu AD-Computerkonten (Neuinst., Weiterverwenden Computername, SID)
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Danke. Und weils hier so gut dazupasst und vielleicht dem einen oder anderen hilft: The Machine SID Duplication Myth Machine SIDs and Domain SIDs Sysprep and Machine SIDs -
Mythen zu AD-Computerkonten (Neuinst., Weiterverwenden Computername, SID)
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Ist es eigentlich Standardverhalten, dass ich ein Computerkonto auch übernehmen kann während der Client/Server aktiv ist? -
Mythen zu AD-Computerkonten (Neuinst., Weiterverwenden Computername, SID)
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Ok. Wir können aber auch mit dem derzeitigen Verhalten problemlos leben. In Zukunft wird man sicherlich über neue Ansätze nachdenken. Flächenbehörde mit best. Anforderungen. Für DCs ganz klar ja, für Server teilweise, für Clients ist eine Konzentration nicht möglich und nicht gewollt. Wäre bei dieser Anzahl und Struktur auch unmöglich. -
Mythen zu AD-Computerkonten (Neuinst., Weiterverwenden Computername, SID)
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Die Rechnernamen sind einem Konzept untergeordnet, die u.a. den Standort, Zugehörigkeit, TelNummern o.ähnliches wiedererkennen lassen. Bei einer 5-stelligen Anzahl... Das ginge technisch sicherlich. Die organisatorische Frage ist da schwieriger : ) (Behörde) Vielleicht eher die Umsetzung, dass die DHCPs beide Records schreiben. Grüße -
Mythen zu AD-Computerkonten (Neuinst., Weiterverwenden Computername, SID)
notimportant antwortete auf ein Thema von notimportant in: Active Directory Forum
Die Prozesse sind von Microsoft designt worden : ) Da rüttelt niemand so einfach daran. Ich würde das auch lieber den DHCPs überlassen. (Oder gibt es noch einen eleganteren Weg?) Aber erstaunlicherweise gibt es so gut wie immer einen Grund, warum etwas nicht auf dem einfacheren Weg gemacht wurde. Das wäre klar. Und im Prinzip nutzen gewisse Teams auch diesen Weg, wenn sie die alten Rechner umbenennen und dann erst den neuen installieren, oder zunächst neue Namen verwenden und dann zurückbenennen. Im Prinzip haben wir auch kein Problem, man kenn seine Vorgehensweisen. Ich habe das zwar vermutet, aber auch Fachliteratur ist ab und an verwirrend geschrieben. Ah, ok, danke, der Link ist interessant mit ein paar Feinheiten. Dass Computeraccounts nicht ablaufen ist klar, damit haben wir zum Glück kein Problem, da andere Prozesse deutlich früher greifen. Danke für die Antworten!