ChritzEDV
-
Gesamte Inhalte
17 -
Registriert seit
-
Letzter Besuch
Alle erstellten Inhalte von ChritzEDV
-
Server 2019 Cluster mit 2 Nodes kleine Probleme
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
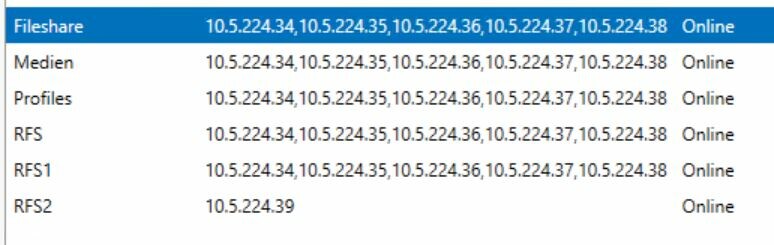
Moin Jan, Ja, ist jetzt auf 2 Hosts. Es ist auch Sinnvoller, das gebe ich ja zu. > Get-Clusterresource -name "Cluster-IP-Adresse" | get-clusterparameter Object Name Value Type ------ ---- ----- ---- Cluster-IP-Adresse Network Clusternetzwerk String Cluster-IP-Adresse Address 10.5.224.35 String Cluster-IP-Adresse SubnetMask 255.255.255.0 String Cluster-IP-Adresse EnableNetBIOS 0 UInt32 Cluster-IP-Adresse OverrideAddressMatch 0 UInt32 Cluster-IP-Adresse EnableDhcp 0 UInt32 Cluster-IP-Adresse ProbePort 0 UInt32 Cluster-IP-Adresse ProbeFailureThreshold 0 UInt32 Cluster-IP-Adresse LeaseObtainedTime 20.11.2019 15:02:33 DateTime Cluster-IP-Adresse LeaseExpiresTime 23.11.2019 15:02:33 DateTime Cluster-IP-Adresse DhcpServer 10.5.224.253 String Cluster-IP-Adresse DhcpAddress 10.5.224.155 String Cluster-IP-Adresse DhcpSubnetMask 255.255.255.0 String Ich hab es schon mit: Update-ClusterIPResource -name "Cluster-IP-Adresse" -release versucht. Bekomme dann aber diese Fehlermeldung: Die Gruppe oder Ressource haben für diesen Vorgang nicht den richtigen Zustand Du hast mich aber auf die richtige Spur gebracht. Damit kann ich arbeiten. Danke Dir! Gruß, Christian -
Server 2019 Cluster mit 2 Nodes kleine Probleme
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
So, ich sagte ja das ich mich melde wenn ich eine Lösung habe. Any ist nicht im Sinne von "any". Ich würde eher "any on different" oder sowas nehmen. Zur Aufklärung: Wenn der Cluster sich auf einem Host befindet muss Virtual eingestellt sein (warum macht man einen Cluster auf einem host? Ist ja unsinnig! Naja, Windows Updates oder Systemfehler auf Betriebssystemebene werden noch immer abgefangen, deswegen). Wenn sich der Cluster auf zwei Hosts verteilt muss Physical eingestelt werden. Ich habe beides getestet. Hinweis: Wie es sich mit einem Cluster mit 3 Nodes auf 2 Host verhält kann ich leider nicht sagen. Das Problem mit der IP bleibt bestehen und ich bin noch immer dankbar für jeden Tipp und wünsche eine angenehme Nacht.
-
Server 2019 Cluster mit 2 Nodes kleine Probleme
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
Ok und danke für die Antworten. Warum die Umsetzung und das Konzept keinen Sinn macht erschließt sich mir zwar nicht (es kommt ja auf die anforderungen an), aber egal. Und wenn eher die Sinn(freiheit) Diskusionsgrundlage (und nicht die Problemstellung) ist dann hilft das keinen und wir können uns alle die Zeit sparen. Ich dachte halt einfach, vieleicht kennt jemand das Problem und kann mir sagen woran es liegt. Dem ist aber scheinbar nicht so. Werd ich halt weiter suchen bis ich eine Lösung habe. Wenn ich eine habe poste ich diese natürlich noch. PS: Soweit ich das sehe befinde ich mich nicht in einer unsopporteten umgeben und bin auch der Meinung das es so funktioniert, warum sollte es auch nicht? PSS: ich hatte schon mit so einigen Dienstleistern zutun bei dennen mein Wissen deutlich höher war als das derrer. Ich war selbst mal Dienstleister. Ich kann zwar keine schönen Zertifikate (bis auf eine Cisco CCNA) vorweisen, aber die sind eh das Papier nicht Wert auf dem sie gedruckt sind. Trotzdem nochmals Danke das Ihr mir Eure Zeit geopfert habt. -
Server 2019 Cluster mit 2 Nodes kleine Probleme
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
Moin, dem risiko bin ich mir durchaus bewusst. Den Cluster gibt es auch nicht wegen des Failover in dem Sinn. Hier gehts eher um das Thema Windows Updates ohne das die Shares weg sind. Außerdem ist dein Zitat nur eine "Empfehlung" und kein "es ist nicht supportet" Würde ja auch nicht zu diesem passen: "Cluster Virtual Machines on OnePhysical Host" aus: https://docs.vmware.com/en/VMware-vSphere/6.5/vsphere-esxi-vcenter-server-651-setup-mscs.pdf Bei einem Punkt bin ich allerdings etwas stutzig in der definition: OptionDescription None Virtual disks cannot be shared by other virtual machines. Virtual Virtual disks can be shared by virtual machines on the same server. Physical Virtual disks can be shared by virtual machines on any server. aus:https://docs.vmware.com/en/VMware-vSphere/6.7/com.vmware.vsphere.html.hostclient.doc/GUID-21970178-EA9A-4CD6-8EBB-A714B267CF29.html Ist mit der Aussage hinter "Physical" auch eine vm auf demselben Server gemeint? Ist ja "any" ohne "without". Deswegen habe ich Physical gewählt um die vm bei Bedarf eben doch zu verschieben. Ich werde heute abend wenn keine Nutzer mehr da sind mal den einen Node verschieben. Mal sehen ob es was nützt. Danke und Gruß, Christian -
Server 2019 Cluster mit 2 Nodes kleine Probleme
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
Ich lese mir das mal durch, danke. Der Shared Storage ist aber über das SAN gegeben und es geht ja auch alles. Ich kann ja die rollen verschieben so oft ich will ohne fehler. Auch den Cluster kann ich problemlos verschieben. Bis eben auf die merkwürdige Meldung mit der IP. So, habs gerafft. Ist spät. Hab gedacht Du meintest mit Typ den Bus Shared. Das hab ich konfiguriert. Und zwar Physikal weil sich beide VMs auf dem gleichen host befinden. Bleibt noch die frage, was meinst du mit "typ"?
-
Server 2019 Cluster mit 2 Nodes kleine Probleme
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
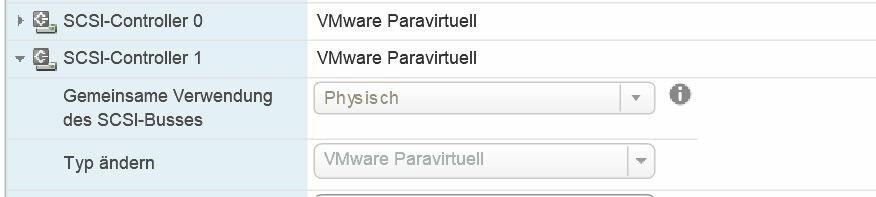
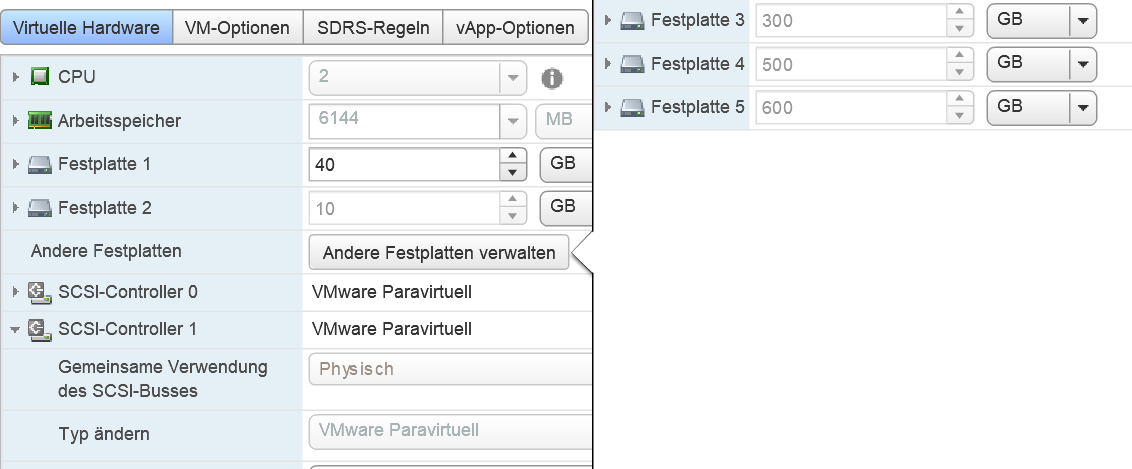
Comp Mode: Physikal Controller: Paravirtuell Auf Controller 1 ist nur die boot disk, natürlich nicht shared Auf Controller 2 sind die shared disks Entschuldige, SCSI Bush Sharing sagt mir erstmal nix, hab ich was übersehen/lesen? Warum ich das mit rdms machen? Weil ich es nicht besser weiß. Das ist mein kenntnisstand. Ist es falsch es so zu machen? Gibt es andere wege die einfacher und zuverlässiger sind? @nils: das habe ich mir auch schon gedacht. Dann müsste ja aber zumindest der cluster da bleiben wenn der 2te node mit den shared disk heruntergefahren wird weil ja die erste vm auch der "halter" der rdm ist. Es ist aber egal welche vm ich abschalte. Der cluster geht immer runter. -
Server 2019 Cluster mit 2 Nodes kleine Probleme
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
Auf dem SAN habe ich eigene luns eingerichtet die dann über fc an die ESXen gegeben werden. Dann der ersten vm im Cluster diese als RDM und der anderen vm als bestehenden Datenspeicher. Beides auf dem 2ten virtuellem scsi controller mit der gleichen zuordnung (was auf 1.1 ist ist auch bei dem 2ten auf 1.1)
-
Server 2019 Cluster mit 2 Nodes kleine Probleme
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
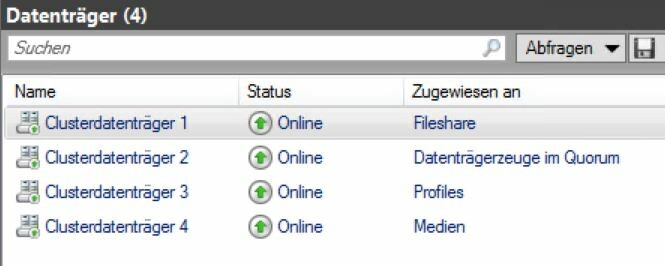
Ich versuche mal die fragen so gut ich kann zu beantworten. Das Quorum habe ich über den Wizard des Cluster-Managers eingerichtet. Anbei der snip. Warum das mit dem DHCP ist weiß ich eben leider auch nicht. Bei einem ipconfig ist sie niegends eingetragen. Ich habe im DHCP die Adresse mal geblockt um herraus zu finden ob sie erreichbar ist. Ist sie aber nicht. Auch im Server Manager taucht sie nicht auf. VMware ESXi, 6.5.0, 5969303 als Lenovo Image. Auch das HowTo (entschuldige, aber für meinen begriff ist das auch sowas) von vmware habe ich zu hilfe genommen. Vieleicht nicht zu 100% jeden Punkt davon, das will ich mal nicht behaupten.
-
Server 2019 Cluster mit 2 Nodes kleine Probleme
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
Sorry, wollte nicht "brüllen" sondern mich eher bedanken für Antworten! Also schon einmal danke für die Antworten. Auf dem esxsen habe ich das ganze nach etlichen studieren einiger howtos über rdms gemacht. Windows hat das Qurom auch anstandslos aktzeptiert. Ich kann die Rollen auch ohne probleme von einem Node auf dem anderen schieben. Nur wenn ich ein Node ausmache (z.B. Windows Updates) geht der Cluster Offline. Für den Cluster habe ich eine feste freie IP Vergeben. Der Cluster Test hat auch keine probleme festgestellt. Dem link von testperson nach zu urteilen ist die umgebung so supportet (hab das auch zuvor soweit wie möglich geklärt) Wobei mir grade dies im Dokument auffällt was ich definitiv nicht gemacht habe. " 2. Modify advanced settings for a virtual SCSI controller hosting the boot device. Add the following advanced settings to the VMs node: scsiX.returnNoConnectDuringAPD = "TRUE" scsiX.returnBusyOnNoConnectStatus = "FALSE" " das werde ich morgen mal setzen. Anbei noch ein snip der config von einem Node Und nochmals danke.
-
Server 2019 Cluster mit 2 Nodes kleine Probleme
ChritzEDV hat einem Thema erstellt in: Windows Server Forum
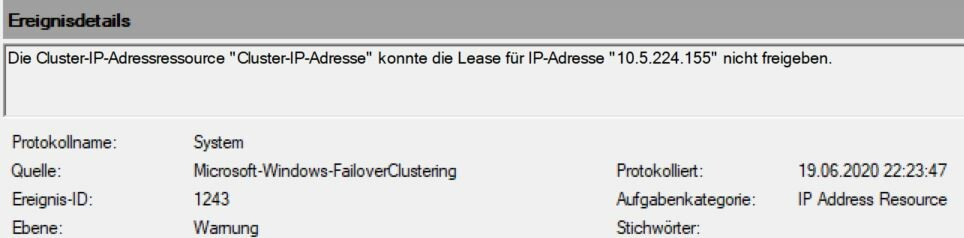
Hallo zusammen, ich habe eine Frage bei der mir das "allwissende" Google nicht mehr weiter hilft. Ich habe einen Cluster als Fileserver mit 2 Nodes über Quorum erstellt. Er läuft auch soweit wie es sein sollte. Bis auf 2 Probleme. Problem1 (komisch aber nicht so dramatisch): Wenn ich den Cluster auf einem Node verschiebe (mit Anhalten -> Rollen ausgleichen) bekomme ich eine Warnung: "Die Cluster-IP-Adressressource "Cluster-IP-Adresse" konnte die Lease für IP-Adresse "xxx.xxx.xxx.155" nicht freigeben." Das war eine DHCP Adresse von einem Node bevor dieser eine Feste bekommen hatte. Ich finde keine vernünftigen Ansätze zu dem Problem (wenn es überhaupt eines ist). 2tes Problem (schwerwiegend): Wenn ich einen Node anhalte ist alles gut. Wenn ich nun aber den angehaltenen Node herunterfahre geht auch der Cluster offline. Hab jetzt gelesen das MS sagt das bei 50% der Cluster herunter gefahren wird. Passiert das deswegen? Dann frag ich mich aber, warum hier nichts darüber steht: https://docs.microsoft.com/de-de/windows-server/failover-clustering/deploy-two-node-clustered-file-server Kann mir da BITTTEEE jemand weiter helfen, DANKE! Kurz zu den Grundlagen: Unterbau sind 2 ESXis im Cluster an einem SAN. Den Filecluster betreibe ich als Speicherort für die Profile einer Remote Desktop Farm. Gruß, Christian -
RemoteApp per GPO auf Session Host
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
Das hört sich schonmal gut an. Es wird lange nicht alles von Datev genutzt, was es könnte. Die Einstellungen für Datev als RemoteApp hab ich mir mal angesehen. Nicht unkompliziert, aber auch keine Wissenschaft. -
RemoteApp per GPO auf Session Host
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
Hmmm, das klingt nicht berauschend. Hört sich ein wenig wie "Drucker per GPO" an. Das läuft auch nicht so rund hier. Die bisherigen Tests sehen recht gut aus. Ansich geht es auch um "nur" 3 Anwendungen als RemoteApp. Davon ist eine Datev (RemoteApp ist freigegeben), ein Programm was bei uns von jeher als RDP Datei (die sagten auch von anfangen, dass es nicht supportet wird) läuft, und ein Programm für die Zeiterfassung, was bei uns zum Teil auch bereits seit jeher als RDP Datei funktioniert. Über die 4 Arbeitsserver möchte ich erreichen, dass ich Systeme Updaten kann, ohne gleich alles lahm zu legen. Wir haben hier einen 24/7 Betrieb bei dem es schwer ist, Wartungsfenster zu bekommen. (sind eine Einrichtung im Sozialem Bereich wo Bewohner 24/7 betreut werden). Außerdem kann ich Datev nicht mit dem anderen Programm auf einer Maschine nutzen. Beide bedienen sich CrystalReports aber in verschiedenen Versionen mit eigenen Anpassungen. Der derzeitige Aufbau mit Fat Clients ist für uns in der IT (2 Mann für ca. 150 Clients ohne Aussicht auf Verstärkung) so langsam nicht mehr zu stemmen. Ich erhoffe mir mit Einführung von RDS den Wartungsaufwand zu verringern und gleichzeitig die Verfügbarkeit zu erhöhen. Zum glück haben wir keine CAD Anwendungen oder was extrem an Grafik anspruchsvollem. Die Programme sind recht simpel gestrickt, verwalten aber große Datenmengen (auf 3 SQL Servern). Nur als Hintergrund Info, ich bin hier im Unternehmen seit gut 1nem Jahr. Mein Vorgänger ist in Rente gegangen. Die gesamte Struktur ist seit gut 10 - 15 Jahren nicht verändert wurden. Dafür habe ich 2 nette Server und ein SAN bekommen und erstmal ordentlich virtualisiert. Jetzt kommt nach und nach der Rest. Danke nochmal für Deine Hilfestellung. -
RemoteApp per GPO auf Session Host
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
Danke für den Tipp und danke für die Hilfe. Ich hätte wohl noch stunden nach etwas gesucht, was kein wirklicher Fehler ist. Denke aber das es auch mit dem REG Eintrag nicht gehen wird. Wenn ich das als Batch mit einer .wcx mache, geht es leider auch nicht weil, aus welchem Grund auch immer, ein Anmeldefenster erscheint in dem steht, dass die angegebenen Anmeldeinformationen nicht richtig sind. Trage ich diese dann ein, geht es. Auch nach einem Neustart des Arbeitsservers, oder nach dem connect auf einem anderen Arbeitsserver ( 4 sind geplant). Selbst nach einem ändern meines Kennworts muss ich dieses nicht erneut angeben. Als Workaround muss ich halt bei der Umstellung auf bei jedem Benutzer einmal die Verbindung manuell herstellen und einmalig die Anmeldeinformationen eintragen (selbst der hacken "Anmeldeinformationen speichern" muss hierbei nicht gesetzt werden). Am SSO liegt es nicht. Das funktioniert sauber, sobald es kein Session Host mehr ist. Später ist genau das geplant, was Du beschreibst. Da es mit dem "file association" nicht funktioniert, werde ich wohl oder übel Office und ein PDF Viewer direkt auf die Arbeitsserver installieren. Unsere "Fachanwendungen" kommen dann als RemoteApps. Diese brauchen keine file association. -
RemoteApp per GPO auf Session Host
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
OK, eintrag doch gefunden, leider. "Die Installation der Standardverbindung wurde abgebrochen. Standardverbindungen können nicht auf Systemen verwendet werden, die Teil einer Bereitstellung mit Remotedesktopdiensten sind." -
RemoteApp per GPO auf Session Host
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
OK, hatte kurz Zeit zum prüfen. Im Session Host (Arbeitsserver) steht nichts diesbezüglich im Eventlog. (Kein Eintrag 1026 "You cannot apply the webfeed policy to any 2012 server or Windows 8 VDI desktop that is part of the RDS collection/deployment.") -
RemoteApp per GPO auf Session Host
ChritzEDV antwortete auf ein Thema von ChritzEDV in: Windows Server Forum
Danke für den Hinweis. Was für ein blödsinn etwas so gutes von ms so zu verhunzen.... -
Hallo ITler, zunächst einmal hat mir das Forum, auch als bisheriges Nichtmitglied, viel weitergeholfen. Jetzt stoße ich aber leider auf ein Problem, das ich mit der Suchfunktion allein nicht lösen konnte. Auch „freund“ google hilft hier leider nicht weiter. Zur Konstellation: Server1 Windows Server 2019: Installierte Rollen: -Remote Desktop Connection Broker -Web Access für Remotedesktop -Remotedesktop-Verbindungsbroker -Remotedesktop Lizensierung Server2 Windows Server 2019 Installierte Rollen Session Host ( Arbeitsserver ) Server3 Windows Server 2019 Installierte Rollen Session Host (RemoteApp Server für Office) Client Windows 10 Zur Einrichtung: Server1 ist soweit eingerichtet. Zertifikate sind mittels Letsencrypt eingespielt. GPOs für Thumbprint, WebURL und SSO und Verteilung der RemoteApps sind gesetzt. Auf dem Client (Windows 10) funktioniert alles hervorragend, ohne irgendwas bestätigen zu müssen, oder einen hacken setzen zu müssen. Auch File Association klappt super. Die Anmeldung auf dem Arbeitsserver verläuft auch ohne jegliches murren, oder mukkeln. Aber bekomme ich die RemoteApps nicht automatisch zugewiesen. Ich kann Sie nur über RemoteApp- und Desktopverbindung bereitstellen. Hier muss ich mich zuvor dann Anmelden. Benutze ich einen Server 2019 ohne installierten Session Host geht auch alles. Sobald ich aber die Rolle Session Host installiere sind die RemoteApps verschwunden. Es ist auch egal, ob sich der Session Host in der Farm befindet, oder nicht. Ich habe keine Idee mehr. Hat Vielleicht jemannd einen Rat? Vielen Dank! Gruß, Christian